El Techo de Cristal de los LLM: Planificación, Memoria y las Capacidades Ausentes según Demis Hassabis
Resumen Ejecutivo: El Futuro según Hassabis
La Tesis: Demis Hassabis (CEO de Google DeepMind) confirma que el escalado bruto de datos ha tocado techo técnico. La próxima generación de IA no será más inteligente por leer más internet, sino por cambiar fundamentalmente su arquitectura de pensamiento.
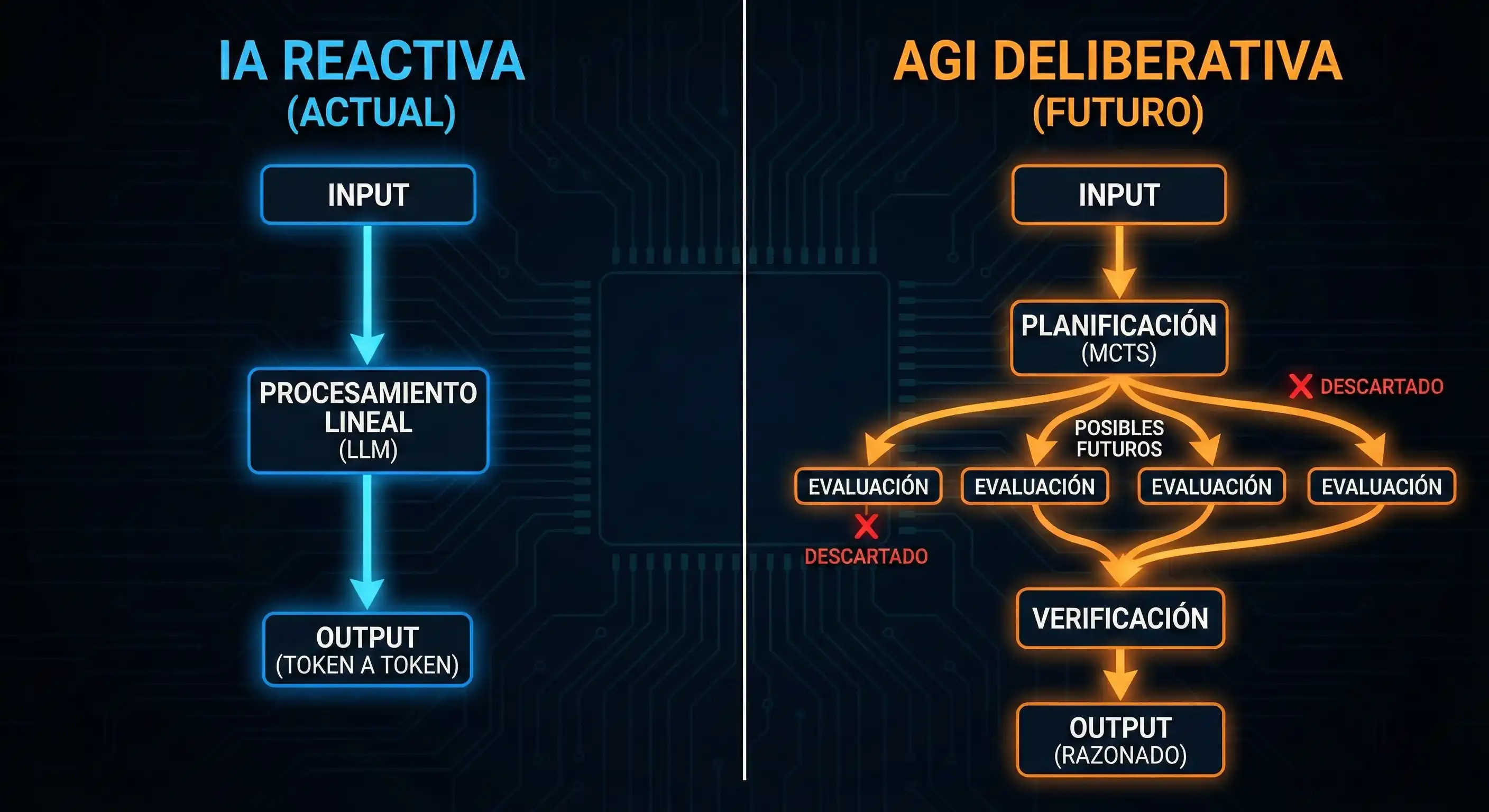
Los modelos actuales son reactivos. El futuro exige la integración de algoritmos de búsqueda (tipo AlphaGo) para que la IA evalúe y simule múltiples rutas de respuesta internamente antes de emitir una solución definitiva.
Superar la limitada ventana de contexto temporal para crear sistemas que posean una memoria de largo plazo, aprendiendo continuamente de la interacción con el usuario sin necesidad de re-entrenamientos costosos.
La combinación de la flexibilidad de las Redes Neuronales con el rigor de la Lógica Simbólica para eliminar las alucinaciones mediante procesos de verificación formal interna.
Implementar estas capacidades aumentará el «cómputo en tiempo de inferencia». Los usuarios deberán aceptar mayor latencia a cambio de una fiabilidad del 100%.
«En 2026, la medida del éxito de una IA no será su velocidad, sino su capacidad de dudar y corregirse.»
El desarrollo de la Inteligencia Artificial se encuentra en un punto de inflexión. Durante los últimos tres años, la industria tecnológica ha operado bajo una premisa casi dogmática: más datos y más potencia de cómputo equivalen linealmente a una mayor inteligencia. Sin embargo, figuras centrales en la historia de la computación, como Demis Hassabis (CEO de Google DeepMind), han comenzado a señalar las limitaciones estructurales de este enfoque.
Aunque los Modelos de Lenguaje de Gran Tamaño (LLM) actuales, como GPT-4 o Gemini, sorprenden por su fluidez lingüística, carecen de los componentes arquitectónicos fundamentales para alcanzar una verdadera autonomía. Según la visión de Hassabis, para dar el salto desde un chatbot avanzado hacia una IA General (AGI) funcional, es necesario resolver tres carencias críticas: planificación, memoria persistente y razonamiento verificable.
El dilema de la planificación: De la reacción a la estrategia
La arquitectura actual de los transformers opera, en esencia, como un sistema de autocompletado hipervitaminado. Funcionan prediciendo el siguiente token (palabra o fragmento de palabra) basándose en probabilidades estadísticas derivadas de su entrenamiento. Este proceso es lineal y reactivo: el modelo no «sabe» cómo terminará una frase o un razonamiento cuando empieza a generarlo.
Hassabis sostiene que el futuro no reside únicamente en escalar estos modelos, sino en dotarlos de capacidades de búsqueda y planificación (Search & Planning).
La herencia de AlphaGo
La propuesta técnica de DeepMind consiste en integrar arquitecturas similares a las que permitieron a AlphaGo vencer a los campeones mundiales humanos. Mientras que un LLM estándar elige la palabra más probable de forma inmediata («Pensamiento Rápido»), un sistema con capacidad de planificación utiliza algoritmos como la Búsqueda en Árbol de Monte Carlo (MCTS).
Esto permite a la IA simular mentalmente múltiples «futuros» o rutas de respuesta, evaluar cuál conduce al resultado lógico correcto y descartar los errores antes de emitir una sola palabra. Es la transición hacia el «Pensamiento Lento» o deliberativo, vital para resolver problemas matemáticos complejos o escribir código de software funcional sin errores lógicos.
Memoria Episódica: Más allá de la ventana de contexto
Uno de los avances más publicitados recientemente ha sido la ampliación de la ventana de contexto (la cantidad de información que un modelo puede procesar en una sola interacción). Sin embargo, existe una distinción técnica crucial: la ventana de contexto actúa como una memoria de trabajo temporal (RAM), no como una memoria episódica o de largo plazo.
Para que la IA sea verdaderamente útil en entornos empresariales o científicos, debe poseer continuidad operativa. En la actualidad, la mayoría de los modelos sufren de amnesia al finalizar una sesión. No recuerdan preferencias, errores pasados ni el contexto de proyectos que duran meses. El desafío técnico para 2026 es implementar sistemas de aprendizaje incremental donde la base de conocimientos del agente se actualice en tiempo real tras cada interacción, sin depender de costosos y lentos procesos de fine-tuning.
Fiabilidad y el fin de las «Alucinaciones»
Las alucinaciones —respuestas inventadas presentadas con total seguridad— no son un fallo («bug») del sistema, sino una característica intrínseca de su naturaleza probabilística. Al no tener un modelo del mundo real, sino solo un modelo estadístico del lenguaje, los LLM actuales no distinguen entre un hecho veraz y una invención plausible.
La solución que plantea la vanguardia de la investigación es la IA Neuro-simbólica. Esto implica hibridar la flexibilidad creativa de las redes neuronales con el rigor inquebrantable de la lógica simbólica y los sistemas formales. Un modelo avanzado debería ser capaz de auditar su propia respuesta, verificando los datos contra fuentes fiables o reglas lógicas antes de entregar el resultado al usuario. Si la IA no puede verificar la información, debería tener la capacidad de reconocer su ignorancia, algo que los modelos actuales rara vez hacen.
El coste oculto del «Pensamiento Profundo»
Implementar estas capacidades transformará radicalmente la experiencia de usuario y la economía de la IA. Entramos en la era del «Compute at Inference Time» (Cómputo en tiempo de inferencia).
A diferencia de los modelos actuales que responden en milisegundos, una IA que planifica, verifica y consulta su memoria necesitará «tiempo para pensar». Esto implica un mayor consumo energético y una mayor latencia. En el futuro cercano, los usuarios deberán elegir entre modelos rápidos y superficiales para tareas triviales, o agentes más lentos, costosos y reflexivos para la toma de decisiones críticas. La inteligencia, al final, dejará de medirse por la velocidad de la respuesta y comenzará a valorarse por la profundidad del razonamiento.