

La inteligencia artificial acaba con el anonimato de las cuentas seudónimas en redes
Resumen Estructurado: El Fin del Anonimato Digital
El contexto: Un estudio exhaustivo de ETH Zurich demuestra que la IA actual puede desanonimizar cuentas seudónimas cruzando rastros dispersos en internet con una precisión del 90%.
Ya no hace falta hackear bases de datos organizadas. Los modelos pueden ingerir años de comentarios caóticos en foros (texto no estructurado) y extraer patrones biográficos ocultos.
El proceso automatizado se divide en cuatro fases letales para la privacidad. Extracción, Búsqueda, Razonamiento y Calibración. Agentes autónomos crean una biografía sintética y la comparan con millones de perfiles en LinkedIn.
Rastrear a un individuo corriente costaba miles de dólares en esfuerzo humano. Ahora, este despliegue de agentes autónomos cuesta entre 1 y 4 dólares por perfil, abriendo la puerta a la vigilancia masiva.
Confiar en que somos «demasiado irrelevantes» para ser investigados ya no funciona. La automatización ha eliminado el escudo logístico que protegía nuestros seudónimos en la red.
«En 2026, tu seudónimo es solo un rompecabezas matemático que la IA resuelve en minutos.»
La creencia de que un seudónimo en internet ofrece un escudo impenetrable de privacidad ha quedado definitivamente obsoleta. En la era actual de los modelos de lenguaje a gran escala, el rastro digital fragmentado que dejamos a lo largo de los años se ha convertido en un rompecabezas trivial de resolver para la inteligencia artificial. Un exhaustivo estudio reciente titulado Large-scale online deanonymization with LLMs, firmado por investigadores de primer nivel como Simon Lermen, Daniel Paleka, Nicholas Carlini y Florian Tramèr, demuestra que desenmascarar a un usuario anónimo ya no requiere un arduo trabajo de investigación humana. Mediante el uso de agentes autónomos, el sistema logra identificar correctamente identidades reales con un porcentaje de acierto del sesenta y ocho por ciento a una precisión del noventa por ciento, pulverizando los métodos clásicos que rozaban un margen de éxito casi nulo.
El salto de los datos estructurados al texto libre
Históricamente, la desanonimización de grandes bases de datos dependía de la disponibilidad de información altamente estructurada. Un caso fundacional y ampliamente estudiado fue el famoso ataque al premio de Netflix en el año dos mil ocho, donde los investigadores lograron identificar a usuarios anónimos cruzando y alineando calificaciones numéricas muy específicas sobre películas. Sin embargo, la revolución que plantea este nuevo paradigma radica en la capacidad de los modelos para operar directamente sobre texto arbitrario y no estructurado, como pueden ser miles de comentarios sueltos en foros de Reddit o discusiones técnicas en Hacker News.
Hasta ahora, los usuarios asumían que los pequeños detalles irrelevantes de su vida quedaban protegidos por el enorme y caótico volumen de información existente en la red, un concepto defensivo conocido en ciberseguridad como oscuridad práctica. Hoy, los modelos de lenguaje de última generación volatilizan esa fricción natural procesando millones de tokens para extraer un mapa de identidad estructurado a partir del ruido.
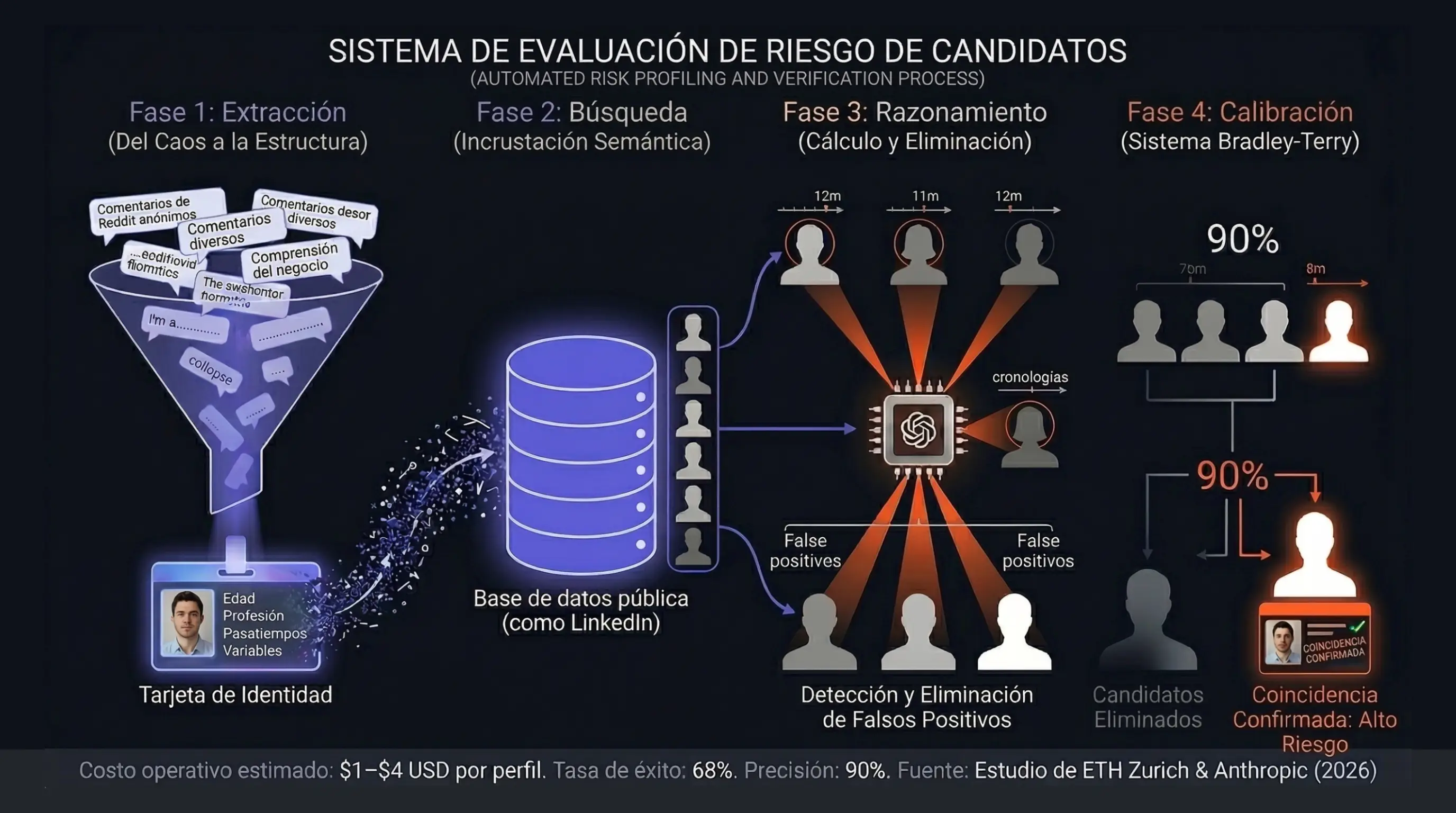
El marco técnico de extracción y calibración
Para lograr esta desanonimización masiva a escala industrial, el equipo de investigadores desarrolló una arquitectura de trabajo automatizada y modular conocida como el marco ESRC, acrónimo de las fases de extracción, búsqueda, razonamiento y calibración. En la fase inicial de extracción, agentes equipados con modelos como Gemini 3 Pro asimilan el historial completo de publicaciones sin estructura y lo sintetizan en perfiles biográficos que detectan desde datos demográficos y trayectorias profesionales hasta aficiones de nicho y estilos de redacción. Tras consolidar esta huella, el sistema emplea modelos de incrustaciones semánticas para buscar posibles coincidencias buceando entre millones de perfiles públicos de internet, como cuentas de profesionales en LinkedIn.
La fase más crítica y costosa del proceso recae en el esfuerzo de razonamiento iterativo. En lugar de confiar ciegamente en la similitud semántica inicial, un modelo de alta capacidad analítica de la talla de GPT-5.2 examina la lista de candidatos preseleccionados para verificar detalles biográficos sutiles que la mera coincidencia vectorial no es capaz de discernir. Finalmente, para garantizar una alta precisión y contener la tasa de falsos positivos, la inteligencia artificial ejecuta una etapa de calibración mediante torneos de estilo suizo. En este paso, el modelo compara los emparejamientos de perfiles cara a cara, ajustando las puntuaciones de certeza técnica mediante el sofisticado sistema de calificación de Bradley-Terry para descartar las identidades menos probables de manera completamente autónoma y matemática.
Viabilidad económica y rastreo temporal
Los investigadores validaron esta compleja infraestructura bajo escenarios empíricos de enorme dificultad técnica. Uno de los experimentos más reveladores fue el emparejamiento temporal, donde el sistema tuvo que analizar el historial de un mismo individuo en la plataforma Reddit cuyas publicaciones estaban separadas por una brecha temporal de un año entero. Los agentes lograron vincular las cuentas demostrando que, a pesar de que los temas de conversación superficiales varíen, la microinformación subyacente de la persona y sus estructuras sintácticas permanecen estables. Las simulaciones del estudio extrapolan que, incluso enfrentándose a un mar de cien millones de candidatos globales, el sistema conservaría el poder computacional suficiente para identificar correctamente a un veintisiete por ciento de los perfiles manteniendo una precisión del noventa por ciento.
Lo que eleva este desarrollo de un mero experimento académico a una amenaza sistémica es su ridículo coste operativo y su escalabilidad lineal. Desplegar esta infraestructura de agentes para rastrear, procesar el texto y confirmar identidades conlleva un gasto que oscila entre tan solo uno y cuatro dólares por usuario analizado. Esta dramática reducción de costes transforma una labor de inteligencia de fuentes abiertas, antes reservada a agencias estatales o procesos forenses sumamente caros, en una herramienta de vigilancia masiva al alcance de cualquier corporación o actor malicioso.
El ecosistema digital frente a la automatización
Esta pérdida definitiva de la privacidad por la desaparición de los cuellos de botella económicos choca con el actual marco de derechos civiles y abre debates urgentes sobre seguridad nacional en este mismo año. Si la fricción logística para espiar a ciudadanos anónimos ya no existe, el potencial de cruzar historiales de foros para trazar expedientes ideológicos completos sin necesidad de órdenes judiciales es técnicamente factible y extraordinariamente barato. Es esta misma escalabilidad letal la que apuntala las reticencias de grandes laboratorios de inteligencia artificial a ceder infraestructuras puras a gobiernos y agencias de defensa.
Frente a un panorama donde el anonimato ha sido hackeado por la fuerza bruta del procesamiento del lenguaje, la última línea de defensa recae en el diseño ético y las restricciones técnicas de las propias interfaces de los modelos fundacionales. Si los ecosistemas de inteligencia artificial no rechazan nativamente las instrucciones de desanonimización no consentida, en el corto plazo cualquier opinión, consulta de salud o debate firmado bajo un seudónimo en la red constituirá, sin margen de error, una declaración expuesta ante el mundo con nombres y apellidos.
Fuentes verificadas
- 01. La IA acaba con el anonimato en redes: así de fácil es desenmascarar cuentas
- 02. Large-scale online deanonymization with LLMs (Estudio original)
- 03. LLMs killed the privacy star, we can’t rewind, we’ve gone too far
- 04. AI Can Unmask Anonymous Users at Scale
- 05. Los LLM y la nueva era del desenmascaramiento online





