

Wan 2.7 de Alibaba consolida la edición de video multireferencia
Resumen técnico y puntos clave
El contexto: Alibaba Cloud revoluciona la generación de video con Wan 2.7, abandonando el simple text-to-video para adoptar una arquitectura de composición compleja basada en hasta cinco referencias multimodales simultáneas.
El modelo aísla atributos específicos como el movimiento de cámara o la iluminación para mapearlos matemáticamente sobre nuevos sujetos sin degradación de textura, asegurando un renderizado de salida nativo a 1080p durante 15 segundos.
Las tediosas máscaras manuales desaparecen a favor de directrices en lenguaje natural. El sistema recalcula secuencias alterando variables estéticas mientras conserva intacta la sincronización de audio y la consistencia topológica del metraje base.
Gracias a su API estructurada, el modelo se integra en infraestructuras de renderizado en la nube para automatizar variaciones masivas en campañas publicitarias o generar contenido didáctico localizado de manera asíncrona.
«En 2026, la IA generativa de video deja de ser una fábrica de secuencias aleatorias para convertirse en un motor de posproducción algorítmico y estructurado.»
La generación de video basada en inteligencia artificial ha superado la etapa de las demostraciones visuales inconexas para entrar en el terreno de la producción estructurada. La llegada del modelo Wan 2.7 de Alibaba marca un punto de inflexión en este primer trimestre de 2026 al priorizar el control absoluto sobre la estética visual frente a la simple interpretación de prompts de texto. Este sistema no se limita a crear secuencias nuevas, sino que introduce un paradigma de edición basado en instrucciones y referencias múltiples que permite clonar el movimiento, la iluminación y el estilo de un metraje existente para aplicarlo a sujetos completamente nuevos en resolución nativa.
Arquitectura técnica y transferencia temporal
El verdadero salto cualitativo de esta versión radica en su capacidad para procesar hasta cinco referencias simultáneas de forma coherente. Mientras que los sistemas de la generación anterior sufrían al intentar combinar un rostro específico con una pose extraída de otro clip, el motor interno de Wan 2.7 desglosa los atributos temporales del video fuente de manera aislada. Esto significa que el modelo extrae vectores específicos correspondientes al movimiento de la cámara, la física de la ropa o las transiciones de luz, y los mapea con precisión matemática sobre la estructura de un sujeto nuevo. Todo este proceso se ejecuta en un espacio latente optimizado que garantiza salidas nativas a 1080p hasta quince segundos, sin necesidad de herramientas de escalado externas que suelen degradar la textura fina.
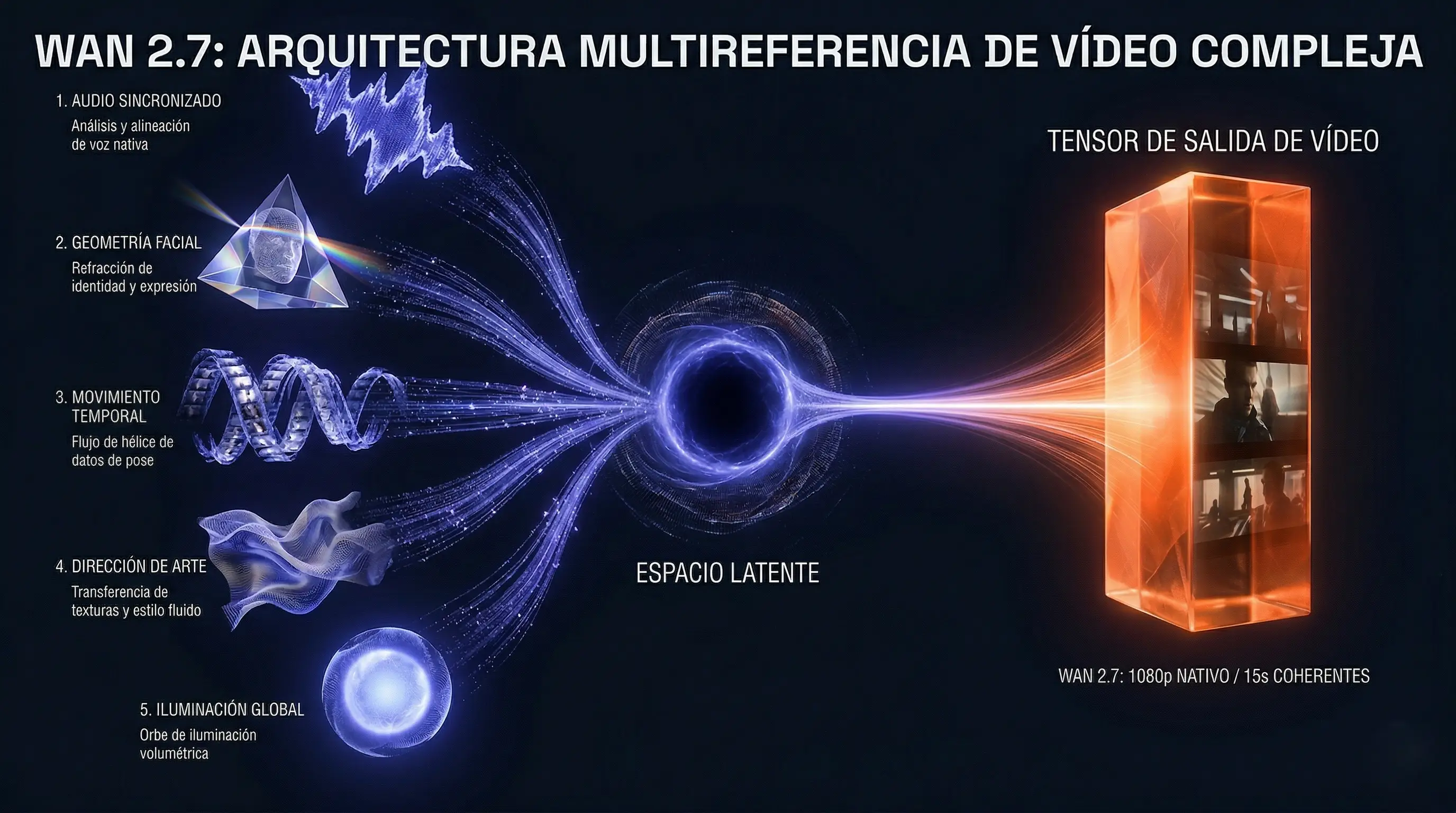
Otra de las piezas clave es su sistema de edición basada en instrucciones. A diferencia de las máscaras de inpainting tradicionales que exigen un flujo de trabajo manual y tedioso frame a frame, el modelo interpreta comandos en lenguaje natural para modificar áreas globales o específicas del metraje. Un director de arte puede solicitar un cambio drástico en la iluminación ambiental o la sustitución del vestuario de un actor central, y el modelo recalcula la secuencia manteniendo intacta la topología original de la escena y la sincronización labial y de audio.
Casos de uso reales en producción
La industria publicitaria y los equipos de crecimiento en redes sociales están encontrando en esta tecnología una vía para iterar campañas a una velocidad sin precedentes. Al utilizar referencias de actores reales o elementos de marca corporativos, los estudios pueden generar variaciones masivas de un anuncio manteniendo la consistencia geométrica del sujeto en diferentes entornos. Un metraje base grabado en un estudio modesto puede transformarse en decenas de localizaciones internacionales aplicando la transferencia de estilo y fondo mediante referencias estáticas, reduciendo drásticamente los costes logísticos y los tiempos de rodaje.
En el sector de la educación y la formación corporativa, la sincronización de audio nativa junto con la preservación estricta de identidad permite escalar la producción de contenido didáctico a nivel global. Los instructores pueden actualizar módulos de video introduciendo nuevos guiones de texto que el modelo sintetiza de manera fluida utilizando el rostro y la voz clonada del profesor original, asegurando que el contenido se mantenga vigente sin requerir nuevas jornadas de grabación en plató físico.
Integración técnica en flujos de trabajo
La adopción a nivel empresarial se facilita mediante una API estructurada que expone estos modos de generación y edición directamente a los desarrolladores. Utilizando llamadas estándar a la infraestructura en la nube de Alibaba, los equipos técnicos pueden automatizar la creación de secuencias controlando fotogramas de inicio y fin para asegurar transiciones perfectas en montajes largos. Los parámetros de configuración permiten definir la resolución deseada, la duración dinámica, y el peso específico que cada imagen o video de referencia tendrá dentro del resultado final. La arquitectura soporta ejecuciones asíncronas para gestionar colas de trabajo pesadas, un requisito indispensable cuando se integran sistemas de renderizado de video en el backend de plataformas de comercio electrónico a gran escala.
Análisis ético frente a la automatización creativa
El control granular sobre la clonación de movimiento e identidad plantea fricciones inevitables en el ámbito de los derechos de imagen y la propiedad intelectual. La facilidad con la que el sistema permite absorber el estilo de dirección de un videoclip existente para aplicarlo a una nueva producción comercial difumina peligrosamente la línea entre la inspiración técnica y la apropiación directa. A medida que estas herramientas se democratizan y sus costes de inferencia descienden a fracciones de centavo por segundo generado, la devaluación del trabajo de los técnicos de efectos visuales y especialistas en posproducción es una realidad innegable. La industria se enfrenta a la urgente necesidad de implementar estándares de trazabilidad algorítmica robustos que permitan identificar el origen sintético de las piezas, especialmente cuando la manipulación de rostros y voces alcanza un grado de fotorealismo indistinguible para el ojo humano.





