

Soberanía de Datos: Guía de Arquitectura RAG Local con Anything LLM y LM Studio
Resumen Estructurado: Soberanía RAG Local
El contexto: Guía técnica para el despliegue de una infraestructura de IA privada y local, desacoplando el motor de inferencia de la gestión documental para garantizar la soberanía de los datos.
Se propone una simbiosis técnica donde LM Studio actúa como el motor de ejecución (usando modelos GGUF y emulando la API de OpenAI), mientras que Anything LLM gestiona el contexto, los agentes y la base de datos vectorial.
El éxito del sistema depende de levantar correctamente el servidor local en el puerto 1234 y configurar estrategias de fragmentación (chunking) adecuadas para equilibrar el uso de memoria RAM con la precisión de búsqueda semántica.
- Capacidades Agénticas: Habilitación de «skills» como búsqueda web, scraping y generación de gráficos.
- Protocolo MCP: Integración del Model Context Protocol para conectar el LLM local con herramientas externas y bases de datos de forma estandarizada.
- Privacidad: Ejecución total en local (CPU/GPU) sin dependencias de la nube.
Esta arquitectura permite a los usuarios pasar de ser consumidores de APIs a propietarios de su infraestructura de IA, asegurando el control total sobre la información confidencial.
Aprende a crear tu IA en local con tus datos
Manual técnico (PDF) con la configuración paso a paso de LM Studio y Anything LLM. Soberanía de datos, diagramas de arquitectura y gestión de VRAM.
Descargar PDFEn un ecosistema digital saturado de APIs de pago y telemetría invasiva, la verdadera revolución es el silencio. Aprende a orquestar un sistema de inteligencia artificial que vive exclusivamente en tu hardware, transformando tu PC en un servidor de inferencia privado y soberano.
La promesa de la Inteligencia Artificial Generativa suele venir con una letra pequeña inaceptable para muchos: la renuncia a la privacidad. Cada prompt enviado a ChatGPT o Claude es un dato que abandona tu jurisdicción. Sin embargo, la madurez de los modelos Open Weights (como Llama 3, Mistral o Phi-4) y la optimización del hardware de consumo han abierto una vía alternativa: la IA Local.
Este artículo no es un simple tutorial de instalación; es una inmersión técnica en la orquestación de dos piezas de software que, combinadas, eliminan la dependencia de la nube: LM Studio como motor de inferencia y Anything LLM como cerebro gestor de contexto.
La Arquitectura del Sistema: Desacoplando el Cerebro de la Memoria
Para entender por qué esta combinación es superior a usar herramientas aisladas, debemos analizar la arquitectura. Estamos construyendo un sistema modular donde separamos la capacidad de razonamiento (LLM) de la gestión del conocimiento (Vector DB).
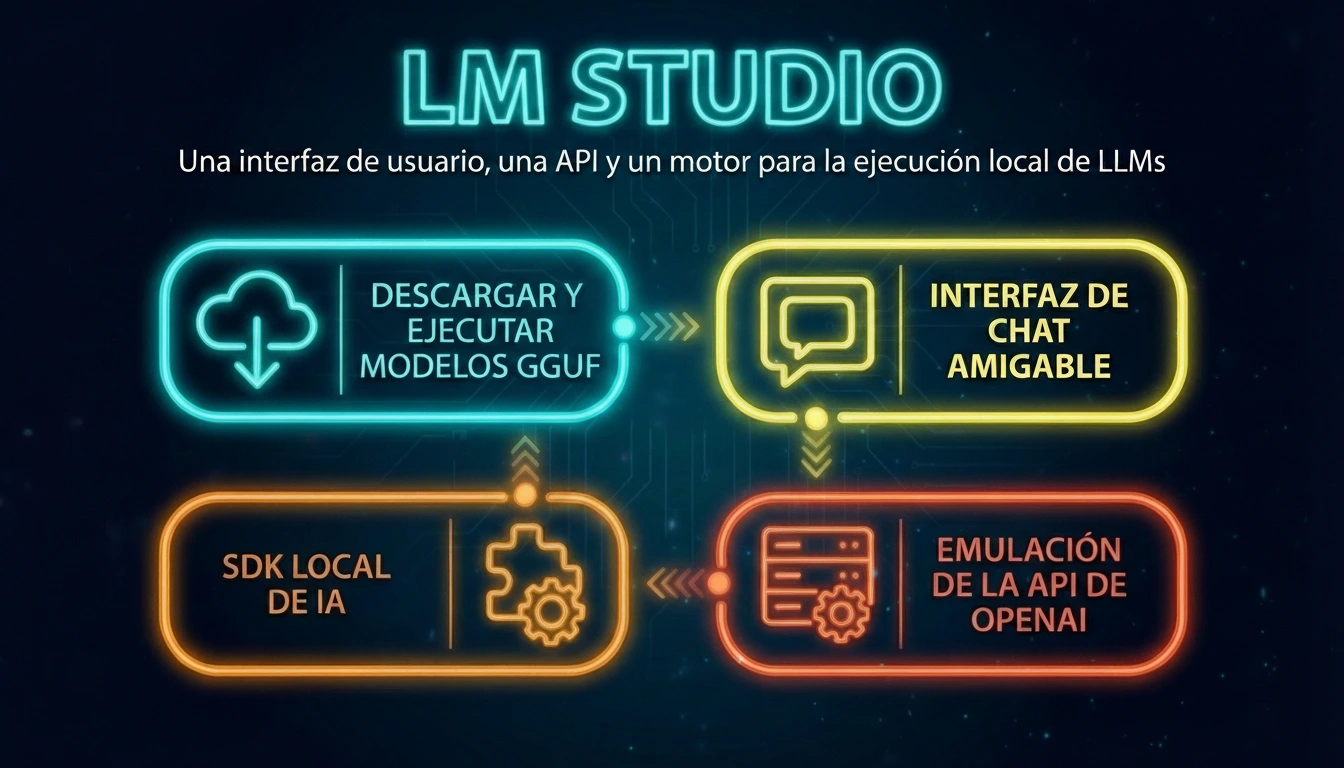
1. El Motor de Inferencia: LM Studio y el Estándar GGUF
LM Studio no es un chatbot; es un entorno de ejecución de alto rendimiento. Su núcleo permite cargar modelos en formato GGUF (GPT-Generated Unified Format), un estándar diseñado para empaquetar tensores, arquitectura y metadatos en un solo archivo binario.
La magia de GGUF reside en la cuantización. Un modelo «crudo» (FP16) requiere cantidades masivas de VRAM. LM Studio permite ejecutar versiones cuantizadas (como Q4_K_M o Q5_K_S), que reducen la precisión de los pesos de 16 bits a 4 o 5 bits. Esto permite, por ejemplo, correr un modelo de 8 billones de parámetros (que normalmente exigiría 16GB+ de VRAM) en una tarjeta gráfica de consumo de 6-8GB con una pérdida de «inteligencia» imperceptible para la mayoría de tareas.
Además, LM Studio actúa como un servidor API local. Al activar su servidor, expone endpoints compatibles con la estructura de OpenAI (/v1/chat/completions), permitiendo que cualquier software externo «hable» con tu modelo local como si fuera GPT-4.
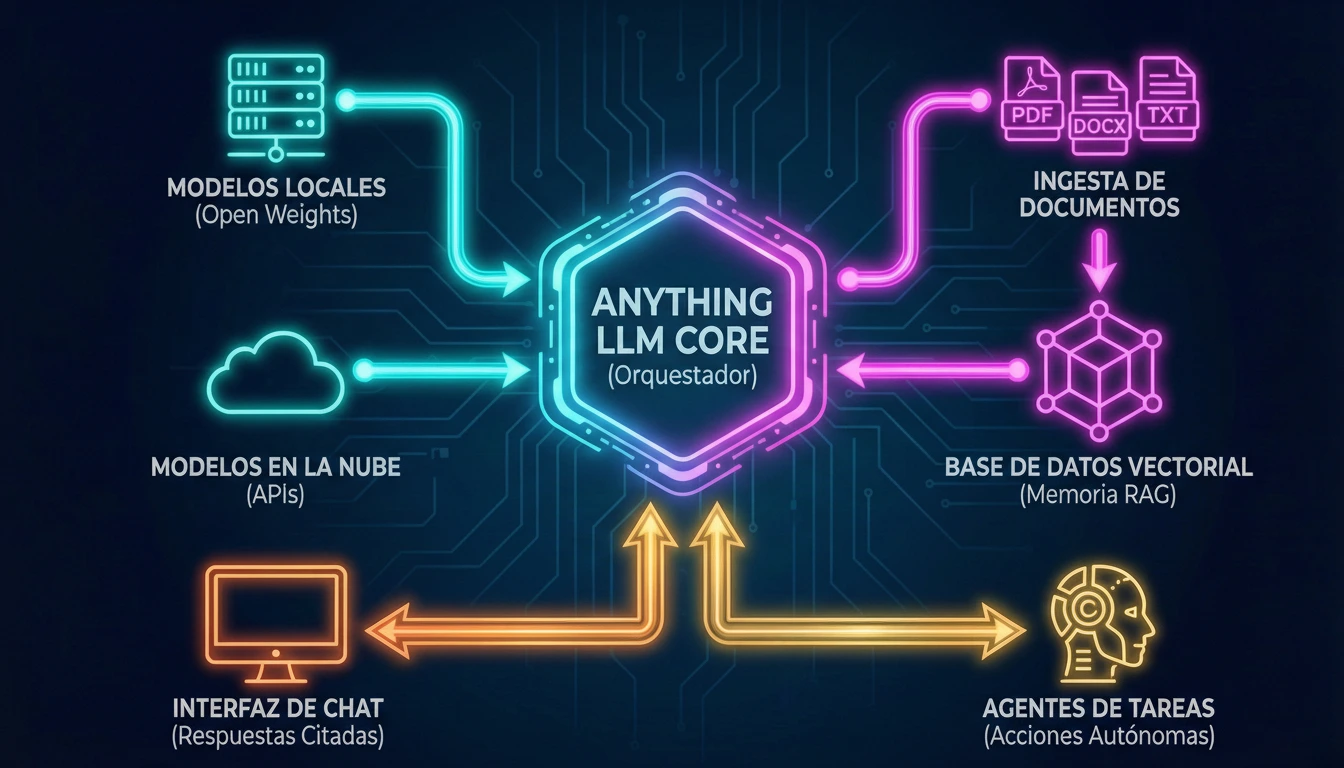
2. El Orquestador: Anything LLM
Si LM Studio pone la fuerza bruta computacional, Anything LLM pone la lógica de negocio. Es una aplicación full-stack que resuelve el mayor problema de los LLMs: la falta de memoria a largo plazo y el desconocimiento de tus datos privados.
Anything LLM integra:
- Gestión de Vectores (Vector DB): Utiliza LanceDB (integrado y sin configuración) para almacenar las representaciones matemáticas de tus documentos.
- Pipeline de Ingesta: Convierte PDFs, DOCX o webs en texto plano, lo limpia y lo prepara para el modelo.
- Sistema de Agentes: Permite que el LLM no solo «hable», sino que ejecute acciones (navegar por web, consultar SQL, etc.).
Implementación Técnica Paso a Paso
A continuación, desplegaremos la infraestructura completa.
Fase 1: Configuración del Servidor de Inferencia (LM Studio)
El objetivo aquí es levantar un servidor que escuche peticiones en el puerto 1234.
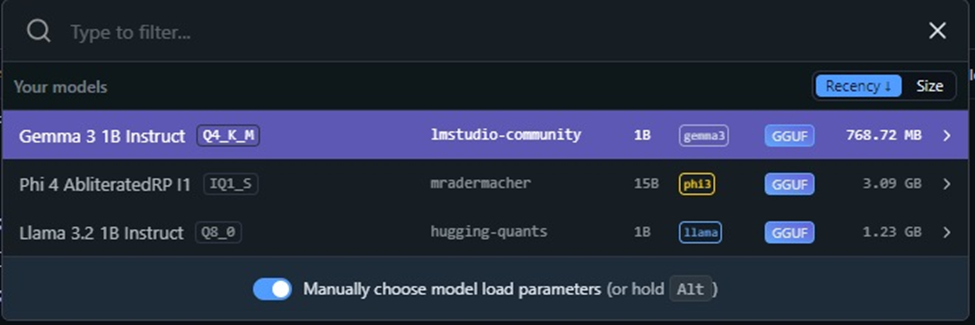
- Adquisición del Modelo:
- En LM Studio, navega a la pestaña «Discover» (Lupa).
- Busca
Llama 3oPhi-4. - Selecciona una variante cuantizada. Recomendación del Arquitecto: Busca la etiqueta
Q4_K_M. Es el punto dulce («sweet spot») entre velocidad y coherencia. - Nota: Verifica que la barra verde de «Likelihood to run» indique que tu GPU/RAM puede soportarlo.
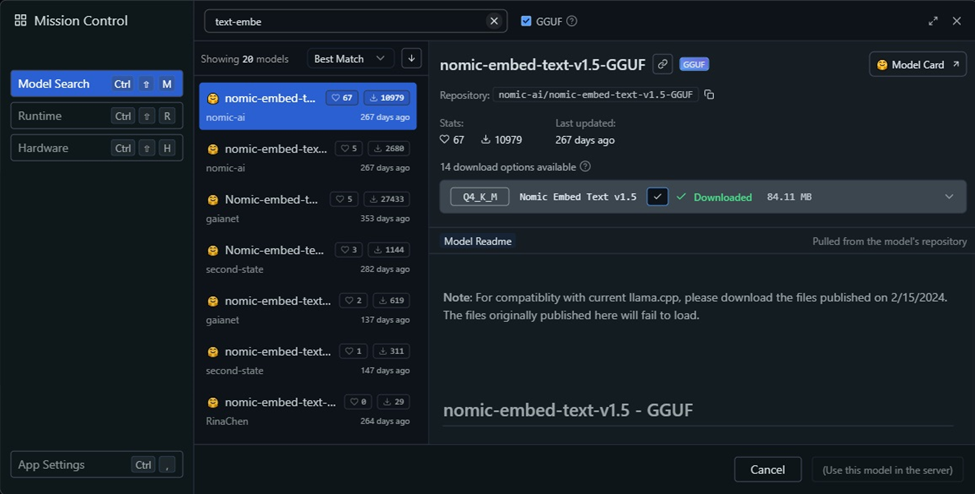
- Modelo de Embeddings (Crítico para RAG):
- Aunque Anything LLM incluye uno por defecto, para máximo rendimiento puedes descargar en LM Studio un modelo específico de embeddings como
nomic-embed-text-v1.5. - Advertencia: LM Studio no puede ejecutar el LLM principal y el modelo de embedding simultáneamente si no tienes recursos de sobra. Si tienes menos de 16GB de RAM, deja que Anything LLM maneje los embeddings internamente.
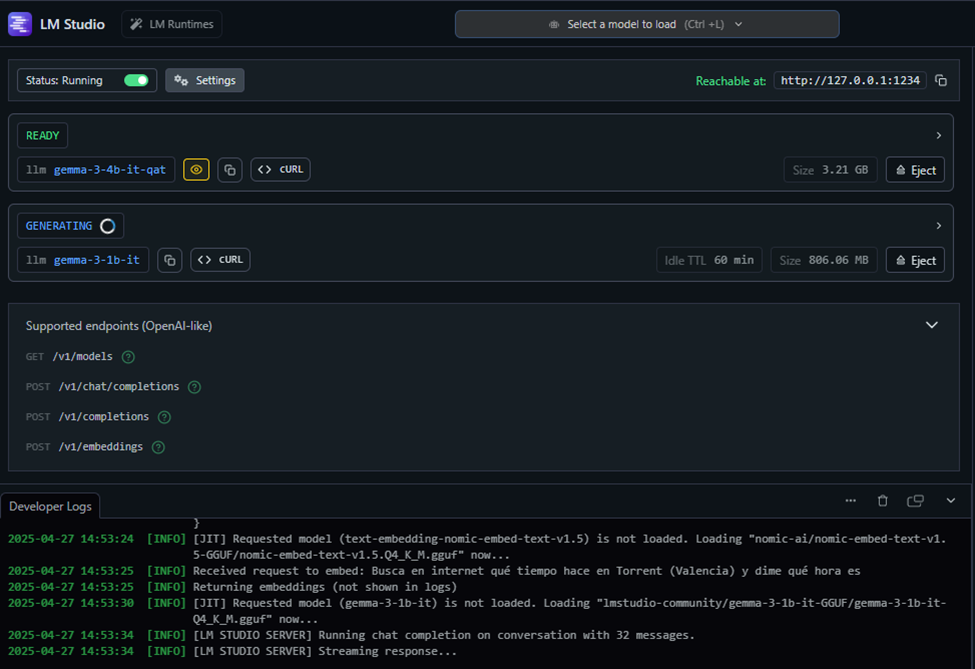
- Despliegue del Servidor:
- Ve a la pestaña «Local Server» (<->).
- Carga el modelo principal en la ranura superior.
- Asegúrate de que el Server Port esté en
1234. - Activa Cross-Origin-Resource-Sharing (CORS) si planeas acceder desde otros dispositivos de tu red.
- Pulsa Start Server. Deberías ver logs verdes indicando que está escuchando en
http://localhost:1234.
Fase 2: Conexión del Cerebro (Anything LLM)
Ahora conectaremos el orquestador al puerto que acabamos de abrir.
- Instalación y Setup: Instala la versión Desktop de Anything LLM.
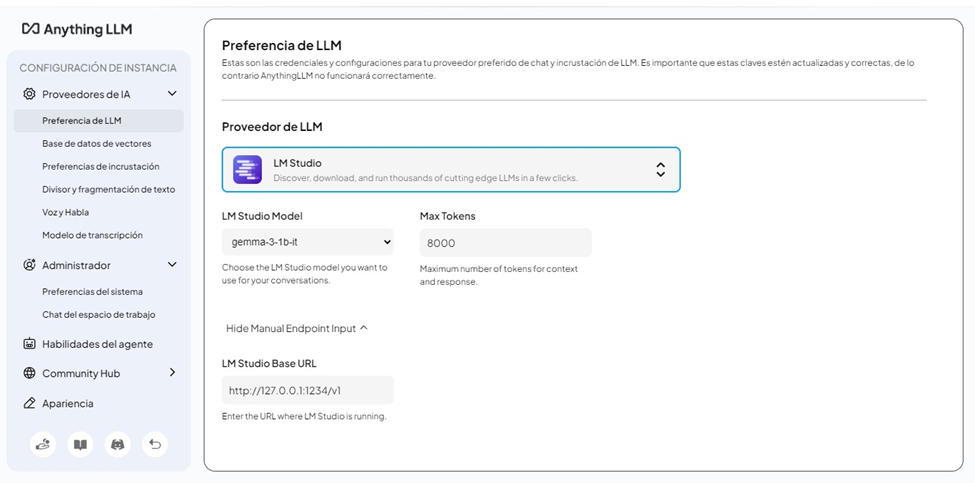
- Vinculación del Proveedor (LLM Preference):
- Dirígete a Settings > AI Providers > LLM.
- Selecciona LM Studio en la lista.
- Base URL:
http://127.0.0.1:1234/v1. - Anything LLM detectará automáticamente el modelo cargado (ej:
llama-3-8b-instruct) y lo mostrará en el desplegable «LM Studio Model». - Token Context Window: Ajústalo según el modelo (ej: 8192 para Llama 3).
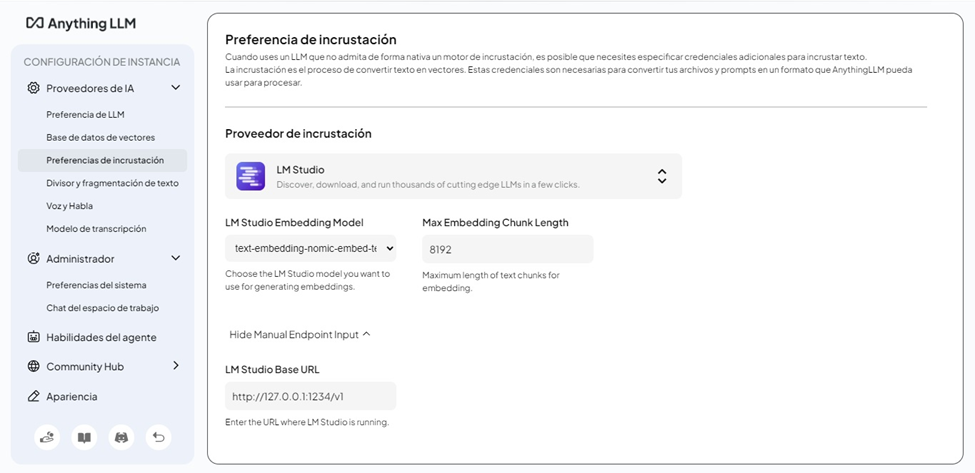
- Configuración de la Base Vectorial:
- En Settings > Vector Database, mantén LanceDB por defecto. Es una base de datos vectorial «serverless» que se ejecuta dentro de la propia aplicación, ideal para mantener todo 100% local sin configurar contenedores Docker adicionales como Milvus o Chroma.
Fase 3: Ingeniería de Datos y RAG
Aquí definimos cómo la IA interactúa con tu información.
- Creación de Workspace: Crea un espacio de trabajo específico, por ejemplo, «Finanzas 2024». Esto aísla los documentos: el agente de Finanzas no sabrá nada de tus documentos médicos.
- Fragmentación (Chunking) – El Arte Oculto:
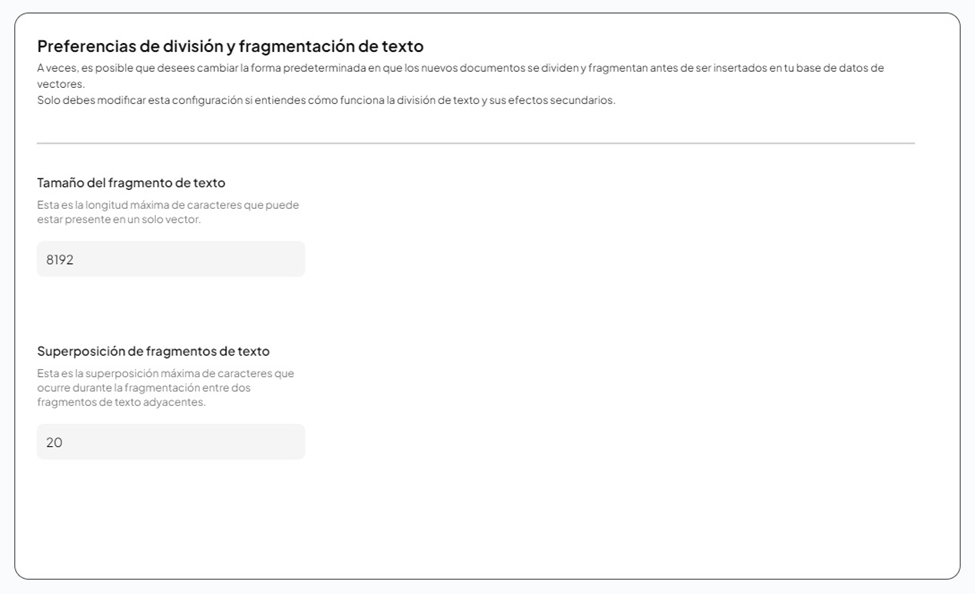
- En Settings > Text Splitting, verás opciones como Chunk Size y Chunk Overlap.
- Teoría: El modelo no lee el PDF entero; lee fragmentos. Si el Chunk Size es muy pequeño (ej: 256), pierdes contexto. Si es muy grande (ej: 8192), diluyes la precisión de la búsqueda vectorial y consumes más RAM.
- Recomendación: Para modelos modernos (Llama 3), un tamaño de 1024 a 2048 caracteres con un solapamiento (overlap) del 10-20% es ideal para equilibrar contexto y precisión.
- Ingesta: Sube tus archivos. Al hacer clic en «Move to Workspace», Anything LLM inicia el proceso de vectorización (embedding), transformando tu texto en coordenadas numéricas y guardándolas en LanceDB.
Capacidades Avanzadas: Agentes y Servidores MCP
Lo que distingue a Anything LLM de un simple chat con PDFs es su capacidad agéntica.
1. Habilidades del Agente (Agent Skills)
Puedes activar herramientas específicas que el modelo decidirá usar cuándo sea necesario:
- RAG Search: La capacidad base de buscar en tus documentos.
- Web Browsing: Permite al modelo salir a internet (via Google/Bing) para contrastar tus datos locales con información en tiempo real.
- Web Scraping: Puedes pedirle «Analiza el contenido de esta URL y compáralo con mi PDF cargado».
- Chart Generation: Capacidad de visualizar datos de tus documentos CSV generando gráficas visuales en el chat.
2. Protocolo de Contexto del Modelo (MCP)
Esta es la vanguardia. Anything LLM soporta MCP (Model Context Protocol), un estándar abierto desarrollado por Anthropic. MCP actúa como un «puerto USB-C» para la IA, permitiendo conectar el LLM a repositorios de GitHub, bases de datos SQL o herramientas como Slack de manera estandarizada, sin tener que escribir integraciones personalizadas para cada servicio.
Análisis Crítico: Cuellos de Botella y Realidad
Como Arquitecto, es mi deber moderar las expectativas con realismo técnico.
- Dependencia del Modelo de Embedding: Si tus búsquedas no devuelven resultados relevantes, raramente es culpa del LLM (Llama 3). Generalmente, es culpa del modelo de embedding (el «bibliotecario» que busca la información). Asegúrate de usar modelos de embedding competentes; el que viene por defecto es básico.
- Velocidad de Inferencia (Tokens/seg): Si no tienes GPU (Tarjeta Gráfica Dedicada), la generación será lenta. RAG requiere «leer» mucho contexto antes de generar la primera palabra. En CPU, esto puede traducirse en latencias de 10 a 30 segundos antes de recibir respuesta.
- Alucinaciones en RAG: Aunque RAG reduce las invenciones, si la respuesta no está en tus documentos y no has configurado un «System Prompt» estricto (ej: «Si no encuentras la respuesta en el contexto, di que no lo sabes»), el modelo intentará rellenar los huecos con su entrenamiento general, lo cual puede ser peligroso en contextos profesionales.




