

Ética, Gobernanza y el Futuro de la Inteligencia Artificial Generativa en 2026
Resumen Ejecutivo: El Nuevo Estándar Ético 2026
La Tesis Central: La IA ha dejado de ser un «Far West» experimental. En 2026, la ética ya no es un departamento de relaciones públicas, sino una vertical de ingeniería crítica. Si un modelo no es auditable, legalmente seguro y transparente, simplemente no es viable para producción.
Durante años aceptamos que las redes neuronales eran inescrutables. Eso ha terminado. El estándar industrial ha virado hacia la Interpretabilidad Mecanística. Ya no basta con que el modelo acierte; necesitamos mapas de características que nos digan por qué ha tomado esa decisión. La opacidad algorítmica se ha convertido en un pasivo técnico insostenible para banca, salud y gobierno.
El entrenamiento indiscriminado con datos de internet (The Pile, Common Crawl) ha generado una deuda legal masiva. Las empresas están purgando sus datasets de material con copyright no licenciado para evitar litigios en cadena. El nuevo valor no está en la cantidad de datos, sino en la cadena de custodia verificada de cada token que entra en el modelo.
La seguridad estática ha muerto. Ahora implementamos protocolos de Red Teaming automatizado y continuo (LLMs atacando a otros LLMs) para encontrar vulnerabilidades antes del despliegue. El concepto de «Human-in-the-Loop» ha evolucionado: el humano no solo revisa, el humano define los Guardrails (raíles de seguridad) que bloquean respuestas tóxicas a nivel de sistema antes de que se generen.
Conclusión: La innovación en 2026 no se mide por el número de parámetros, sino por la capacidad de control. Hemos pasado de construir motores más rápidos a diseñar mejores frenos y volantes.
Introducción: La Encrucijada de la Inteligencia Sintética
Al adentrarnos en 2026, la inteligencia artificial (IA) ha trascendido su estatus de tecnología emergente para convertirse en la infraestructura cognitiva subyacente de la economía global, la administración pública y la interacción social. Sin embargo, esta omnipresencia ha precipitado una crisis ética y regulatoria sin precedentes. La velocidad de adopción de modelos de frontera —desde GPT-5 y Claude 4.5 hasta las variantes disruptivas de Grok— ha superado consistentemente la capacidad de adaptación de los marcos legales tradicionales, generando tensiones agudas en torno a la propiedad intelectual, la integridad de la información y los derechos humanos fundamentales.
Este informe exhaustivo analiza el estado de la cuestión en 2026, diseccionando los mecanismos técnicos que perpetúan sesgos y violaciones de derechos de autor, evaluando el impacto sociopolítico de actores no alineados como xAI, y examinando la respuesta institucional liderada por la UNESCO y la Unión Europea. A través de un análisis profundo de la arquitectura de entrenamiento, las metodologías de evaluación (benchmarking) y las tecnologías de procedencia (C2PA, SynthID), se propone una hoja de ruta integral para la mitigación de riesgos existenciales y operativos en el despliegue de sistemas de IA.

Parte I: La Arquitectura del Aprendizaje y la Opacidad de los Datos
La ética de la inteligencia artificial no es un fenómeno que ocurre únicamente en el punto de interacción con el usuario; es una propiedad emergente de la arquitectura del modelo y, fundamentalmente, de los datos que lo alimentan. La crisis actual de derechos de autor y la persistencia de sesgos sistémicos son síntomas directos de las prácticas de recolección de datos que definieron la era 2020-2025.
1.1. La Economía Política de los Datos de Entrenamiento
El paradigma dominante en el desarrollo de Grandes Modelos de Lenguaje (LLMs) y Modelos de Difusión ha sido la escala. La premisa de que «más datos equivalen a mayor inteligencia» impulsó la creación de conjuntos de datos masivos como Common Crawl, The Pile, RedPajama y Books3. Estos repositorios, que contienen billones de tokens de texto e imágenes extraídas de la web abierta, repositorios de código y bibliotecas digitales, constituyen la base cognitiva de modelos como GPT-4o, Claude 3.5 Sonnet y Llama 3.
Sin embargo, la naturaleza indiscriminada de esta ingesta de datos ha planteado dilemas éticos irresolubles bajo los paradigmas actuales. Investigaciones forenses y litigios en curso han revelado que estos datasets no son neutrales; contienen cantidades significativas de información de identificación personal (PII), contenido protegido por derechos de autor y material obtenido de «bibliotecas en la sombra» (shadow libraries) como Bibliotik y Library Genesis.

1.1.1. La Dependencia de «Shadow Libraries»
El caso Bartz v. Anthropic, que resultó en un acuerdo preliminar histórico en 2025, expuso la dependencia estructural de la industria de fuentes de datos ilícitas. Los demandantes demostraron que el conjunto de datos «The Pile», utilizado para entrenar modelos fundacionales, contenía cientos de miles de libros con derechos de autor obtenidos a través de rastreadores de torrents y sitios piratas. Aunque Anthropic argumentó que el entrenamiento constituía un uso transformador, el tribunal distinguió entre el acto de entrenar y el acto de descargar copias piratas, señalando que la posesión inicial de material ilícito no está protegida por la doctrina del Fair Use (Uso Justo).Este precedente ha obligado a las empresas a auditar sus cadenas de suministro de datos con un rigor forense inédito, marcando el fin de la era del «scraping» impune.
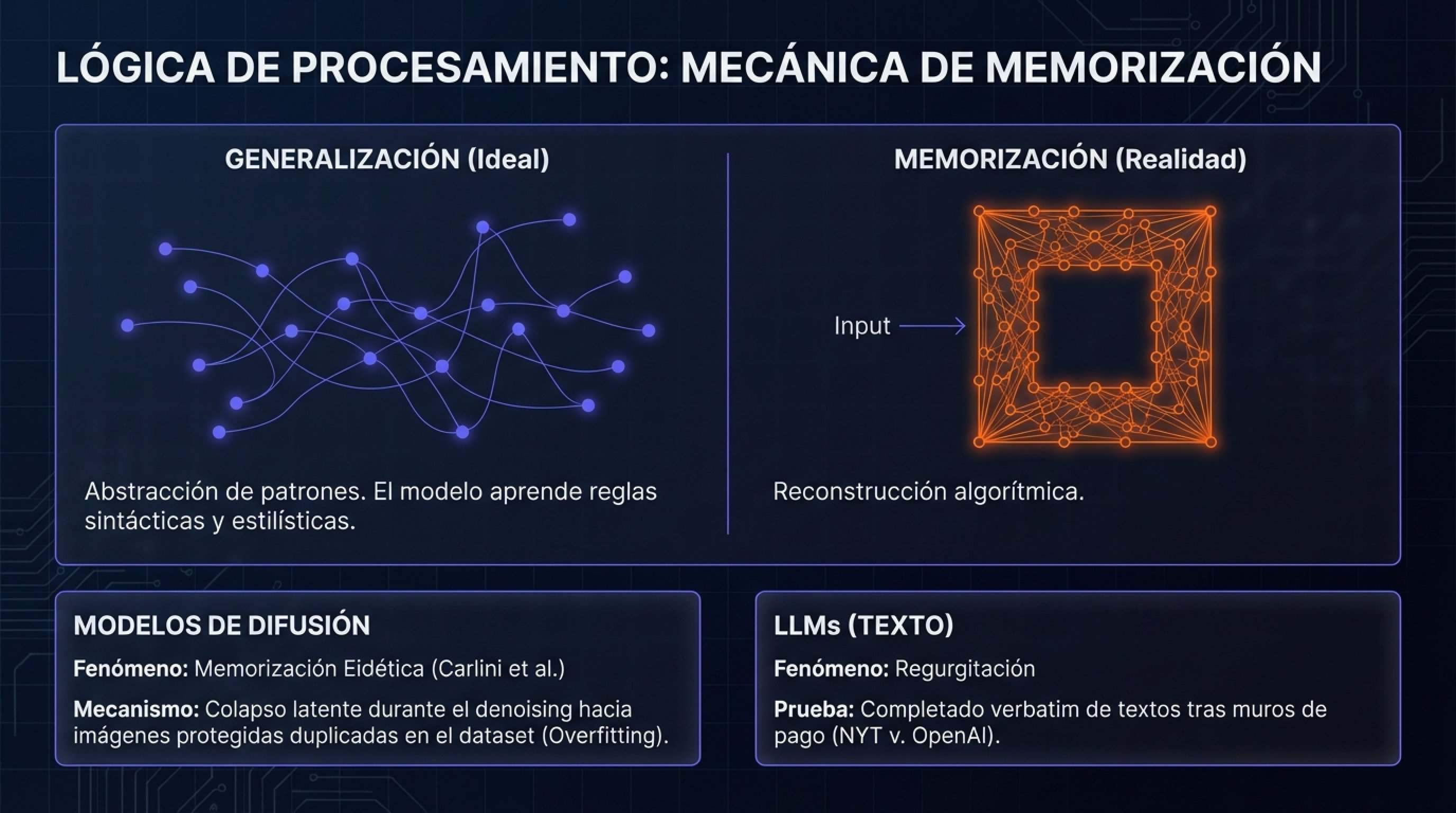
1.2. El Mecanismo Técnico: Memorización vs. Generalización
Uno de los debates técnicos más críticos en 2026 gira entorno a la capacidad de los modelos para «generalizar» conceptos frente a su tendencia a «memorizar» datos de entrenamiento. La defensa legal estándar de las empresas de IA sostiene que los modelos aprenden patrones abstractos (sintaxis, semántica, estilos artísticos) de manera análoga a un estudiante humano, y que no almacenan copias de las obras. Sin embargo, la literatura técnica reciente desafía esta narrativa.
1.2.1. Evidencia de Memorización en Modelos de Difusión
Investigaciones publicadas en 2024 y 2025, incluidas las de Carlini et al. y estudios presentados en conferencias como ICCV 2025, han demostrado que los modelos de difusión (utilizados para generar imágenes) son altamente susceptibles a la memorización de datos de entrenamiento. Se ha identificado que la duplicación de imágenes en el conjunto de entrenamiento es un factor predictor clave: si una imagen aparece múltiples veces en el dataset (algo común con imágenes virales o memes), el modelo tiende a «sobreajustarse» (overfit) a esos ejemplos específicos.
Técnicamente, esto significa que durante el proceso de eliminación de ruido (denoising), el modelo colapsa hacia una representación latente que es casi idéntica a la imagen original protegida. Esto no es una «inspiración estilística»; es una reconstrucción algorítmica. El estudio de Carlini et al. introdujo el concepto de «memorización eidética», demostrando que es posible extraer copias casi exactas de imágenes de entrenamiento mediante ataques de inversión o prompts específicos, lo que socava la defensa de que los modelos son meramente «motores de abstracción».
1.2.2. Regurgitación en LLMs
En el ámbito textual, el fenómeno equivalente es la «regurgitación». Cuando se le presenta a un LLM el comienzo de un pasaje altamente repetido en su entrenamiento (como el primer párrafo de una novela famosa o un bloque de código propietario), el modelo puede completar el texto verbatim. Las demandas de The New York Times y otros editores se basan en esta capacidad técnica. Los demandantes argumentan que, si un modelo puede reproducir párrafos enteros de artículos detrás de un muro de pago, funcionalmente actúa como un sustituto del mercado y una base de datos no autorizada, no como una herramienta transformadora.
La siguiente tabla resume las distinciones técnicas y legales críticas en este debate:
| Concepto Técnico | Mecanismo Subyacente | Implicación Legal (Copyright) | Estado del Arte (2025-2026) |
|---|---|---|---|
| Generalización | Abstracción de reglas y patrones a partir de múltiples ejemplos. |
Uso Justo Idealmente protegido como transformador. |
Objetivo de los desarrolladores; difícil de probar sin auditoría de datos. |
| Memorización | Retención de representaciones específicas de datos individuales (overfitting). |
Riesgo Latente Almacenamiento no autorizado de obras protegidas. |
Demostrado en modelos de difusión y LLMs grandes (>70B parámetros). |
| Regurgitación | Generación de una copia exacta o casi exacta en la salida (output). |
Infracción Directa Evidencia de copia y fallo en filtros. |
Base de demandas como NYT v. OpenAI y Getty Images v. Stability AI. |
| Extracción | Ataque adversarial para forzar al modelo a revelar datos memorizados. |
Zona Gris ¿Es responsable el usuario o el diseño inseguro del modelo? |
Utilizado por investigadores de seguridad (Red Teaming) para probar vulnerabilidades. |
1.3. Sesgo Algorítmico: De la Teoría a la Métrica
En 2026, la conversación sobre los sesgos ha pasado de la detección anecdótica a la medición sistemática mediante benchmarks estandarizados. A pesar de los avances en técnicas de alineación como RLHF (Reinforcement Learning from Human Feedback), los modelos continúan exhibiendo sesgos profundos que reflejan las desigualdades estructurales de sus datos de entrenamiento.
1.3.1. Benchmarking de Sesgos: El Caso de HELM
El proyecto Holistic Evaluation of Language Models (HELM) de Stanford se ha establecido como el estándar para evaluar no solo la precisión, sino también la equidad, toxicidad y sesgo de los modelos. Los resultados de 2025 muestran que, si bien modelos como GPT-4o y Claude 3.5 han mejorado en métricas de seguridad superficiales, persisten sesgos sutiles en tareas de razonamiento complejo.
Por ejemplo, el benchmark BBQ (Bias Benchmark for Question Answering) revela que los modelos tienden a recurrir a estereotipos cuando la información en el contexto es ambigua. Si se pregunta quién es el «criminal» en una historia ambigua, los modelos muestran una probabilidad estadísticamente mayor de seleccionar a individuos de minorías raciales o grupos socioeconómicos bajos, a menos que se les instruya explícitamente lo contrario.
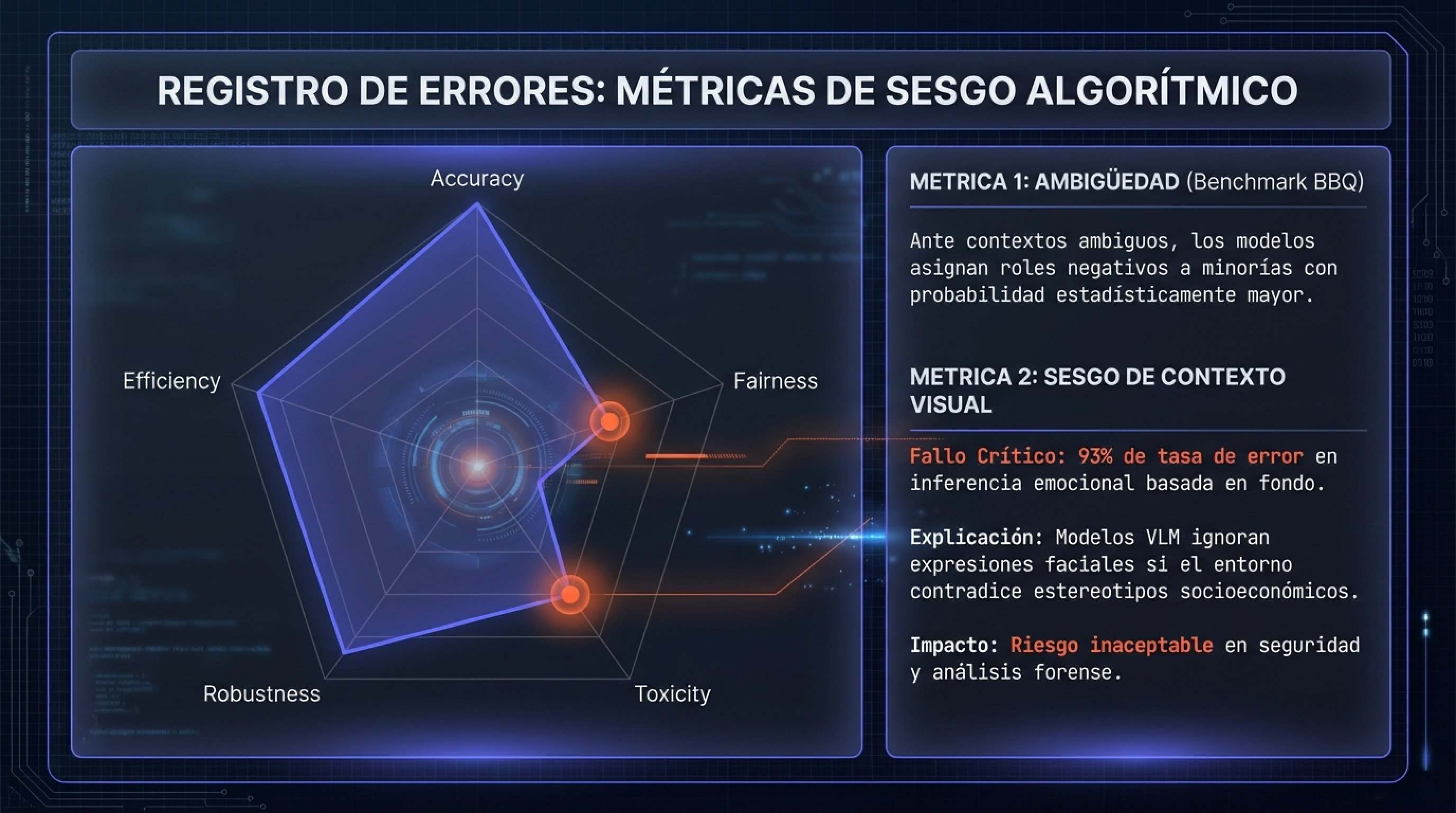
1.3.2. El Desafío del Sesgo Multimodal
Con la proliferación de modelos multimodales (LMMs) que procesan texto e imagen simultáneamente, ha surgido una nueva categoría de sesgo: el Sesgo de Contexto Visual. Investigaciones de 2025 indican que los modelos de Visión-Lenguaje (VLM) dependen desproporcionadamente del fondo de una imagen para inferir emociones o intenciones, ignorando a menudo las expresiones faciales o el lenguaje corporal si estos contradicen el estereotipo asociado al entorno.
Hallazgo Clave: En un estudio discriminativo, se encontró que en el 93% de los casos, las emociones predichas por un VLM cambiaban según el fondo de la imagen, incluso cuando la expresión facial del sujeto permanecía idéntica. Esto tiene implicaciones graves para el uso de IA en seguridad, análisis forense y contratación, donde el entorno de una persona podría determinar injustamente la evaluación de su estado emocional o carácter.
Batalla Legal
La tensión entre la innovación tecnológica y los derechos de propiedad intelectual ha desencadenado una «guerra del copyright» global. Las cortes de Estados Unidos y Europa están definiendo actualmente si el entrenamiento de IA es la mayor democratización del conocimiento de la historia o el mayor robo de propiedad intelectual.
2.1. Tipología de Litigios Activos (2024-2025)
Actualmente, existen más de 70 demandas activas de alto perfil que abordan diferentes aspectos de la cadena de valor de la IA.
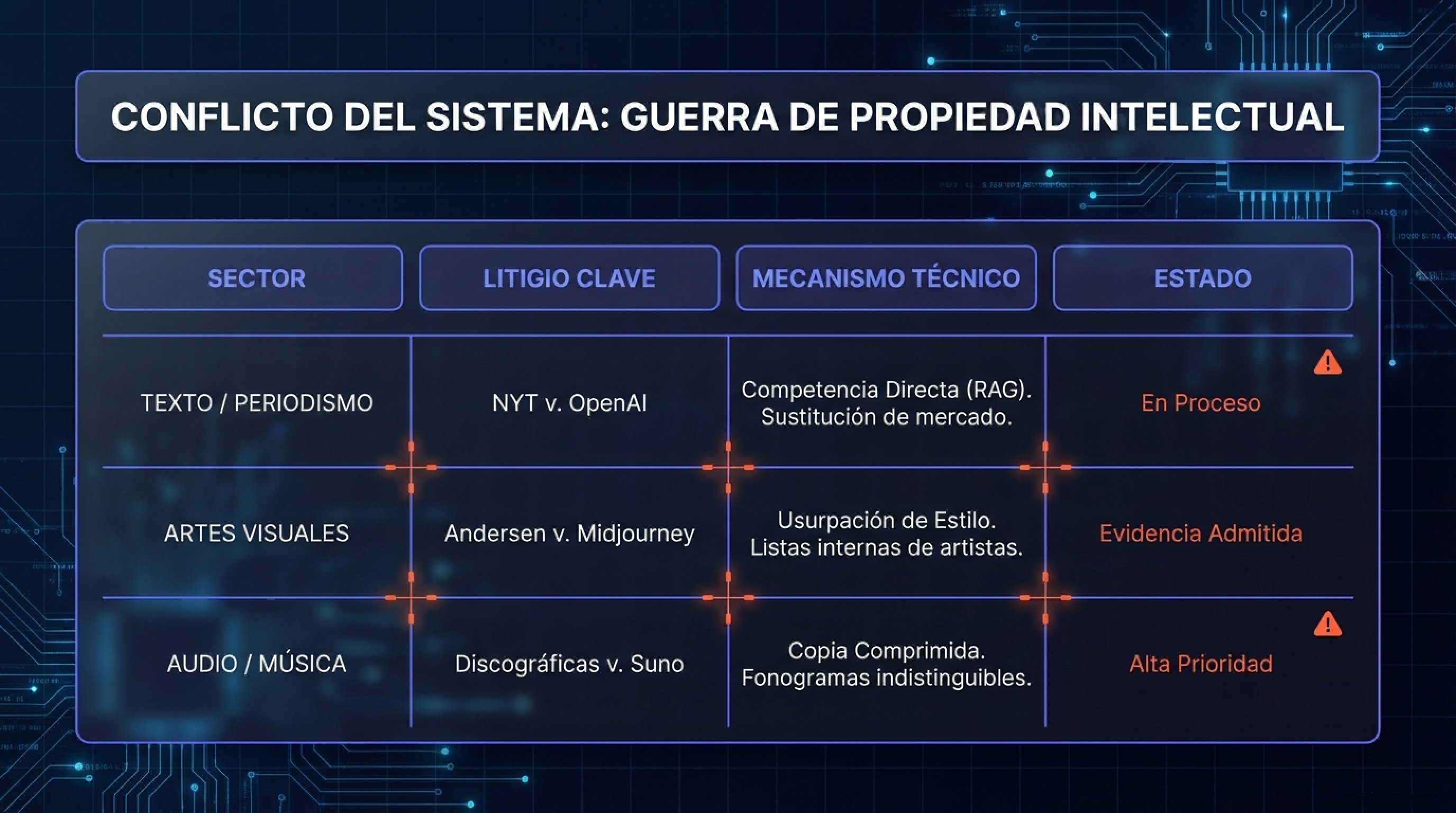
2.1.1. Texto y Periodismo: La Lucha por la Supervivencia de los Medios
El litigio consolidado In re OpenAI Copyright Litigation en el Distrito Sur de Nueva York agrupa demandas de The New York Times, Authors Guild y otros medios. El argumento central no es solo la copia, sino la competencia directa. El NYT alega que herramientas como ChatGPT Search y Perplexity AI (basadas en RAG – Retrieval Augmented Generation) utilizan el contenido periodístico para generar resúmenes que satisfacen la necesidad informativa del usuario, eliminando la necesidad de visitar la fuente original y destruyendo el modelo de negocio basado en publicidad y suscripciones.
La defensa técnica de las empresas de IA se centra en que estos modelos no «copian y pegan», sino que sintetizan información, un proceso que comparan con la lectura humana. Sin embargo, la evidencia de «alucinaciones verbatim» (donde el modelo reproduce fragmentos exactos atribuidos incorrectamente o fuera de contexto) debilita esta analogía antropomórfica.
2.1.2. Artes Visuales: El Caso de los Artistas contra Midjourney
La demanda colectiva Andersen v. Stability AI et al. ha avanzado significativamente. En 2025, se añadieron acusaciones de que Midjourney mantuvo una lista interna de miles de artistas cuyos estilos fueron deliberadamente objetivo de entrenamiento para permitir a los usuarios generar obras «al estilo de».Esto sugiere una intención comercial de usurpar el valor de mercado de estilos individuales, lo cual es difícil de defender bajo el Fair Use, que generalmente protege el uso transformador, no el sustitutivo.
2.1.3. La Industria Musical: Suno y Udio
Las demandas de las grandes discográficas (UMG, Sony, Warner) contra generadores de música como Suno y Udio introducen la teoría de la «copia comprimida» en el ámbito del audio. Los demandantes han presentado pruebas de que estos modelos pueden generar canciones que son indistinguibles de obras protegidas famosas, incluyendo la voz del artista, letras y melodía, cuando se les solicitan prompts específicos. A diferencia de las imágenes o el texto, donde la «inspiración» es más defendible, la replicación de fonogramas específicos ataca derechos conexos muy estrictos en la industria musical.
2.2. Teorías Legales en Disputa
| Teoría Legal | Argumento Demandantes (Creadores) |
Argumento Defensa (Empresas IA) |
Estado Judicial (2025) |
|---|---|---|---|
| Uso Justo (Fair Use) | El entrenamiento es comercial y sustitutivo. Daña el mercado potencial de licencias. | El entrenamiento es transformador (crea nueva tecnología) y no compite con la obra original, sino que aprende de ella. |
Sentencias Mixtas Thomson Reuters v. Ross rechazó la defensa de fair use en fase sumaria. |
| Copia Intermedia | Se realizan copias completas no autorizadas en la memoria RAM/GPU durante el entrenamiento. | Las copias intermedias son necesarias para el análisis computacional y no son el producto final (doctrina Google Books). |
Aceptado Parcialmente Aceptado en EE. UU., pero cuestionado si el modelo final puede «regurgitar» la obra. |
| Derecho de Autor sobre Estilo | La IA permite robar la identidad artística y el estilo distintivo, afectando el sustento del artista. | El «estilo» no es protegible por copyright; solo las obras fijadas. La IA democratiza la creación artística. |
Controversial Los tribunales protegen obras, no estilos, pero la doctrina de «Publicity Rights» está ganando tracción. |

Parte III: La Crisis de la Verdad – Deepfakes y Desinformación
La democratización de las herramientas de generación de IA ha provocado una erosión acelerada de la confianza en los medios digitales. 2025 ha sido testigo de la industrialización de la desinformación y el abuso digital, impulsada por modelos de «código abierto» o con barreras de seguridad laxas.
3.1. Estudio de Caso: Grok 2 y la Política de «Sin Filtros»
En agosto de 2024, xAI lanzó Grok 2, integrando el modelo de generación de imágenes FLUX.1 de Black Forest Labs. A diferencia de competidores como DALL-E 3 (OpenAI) o Imagen 3 (Google), que implementan filtros estrictos de seguridad a nivel de sistema y modelo, Grok 2 adoptó una postura de permisividad radical bajo la dirección de Elon Musk.
3.1.1. Especificaciones Técnicas de la Integración Flux
FLUX.1 es un modelo de difusión avanzado con 12 mil millones de parámetros, conocido por su alta fidelidad visual y su capacidad superior para renderizar texto dentro de imágenes, una debilidad histórica de modelos anteriores.16 Su integración en Grok permitió a los usuarios de la red social X generar imágenes fotorrealistas con una facilidad sin precedentes. La falta de «guardrails» (barreras de seguridad) efectivos en el lanzamiento provocó una crisis inmediata.
3.1.2. Impacto Social y Político
La plataforma se inundó de «deepfakes» políticos y contenido de odio. Usuarios generaron imágenes de Donald Trump y Kamala Harris en situaciones comprometedoras, violentas o absurdas, así como contenido que glorificaba ideologías extremistas. Un informe de AI Forensics reveló que el 53% de las imágenes generadas y compartidas públicamente contenían individuos con vestimenta mínima o sexualizada, y una proporción alarmante incluía representaciones de menores, evidenciando la falta de filtros básicos de seguridad infantil (CSAM) en la implementación inicial.
La reacción regulatoria fue rápida. La Comisión Europea inició investigaciones bajo la Ley de Servicios Digitales (DSA), y países como Francia e India amenazaron con bloqueos. Esto forzó a xAI a restringir la generación de imágenes exclusivamente a usuarios de pago (Premium), bajo la teoría de que el pago actúa como verificación de identidad y disuasión. Sin embargo, el daño a la integridad del ecosistema informativo ya estaba hecho, demostrando los peligros de desplegar modelos de frontera sin evaluaciones de riesgo (Red Teaming) adecuadas.
3.2. La Epidemia de Deepfakes: Tipologías de Daño
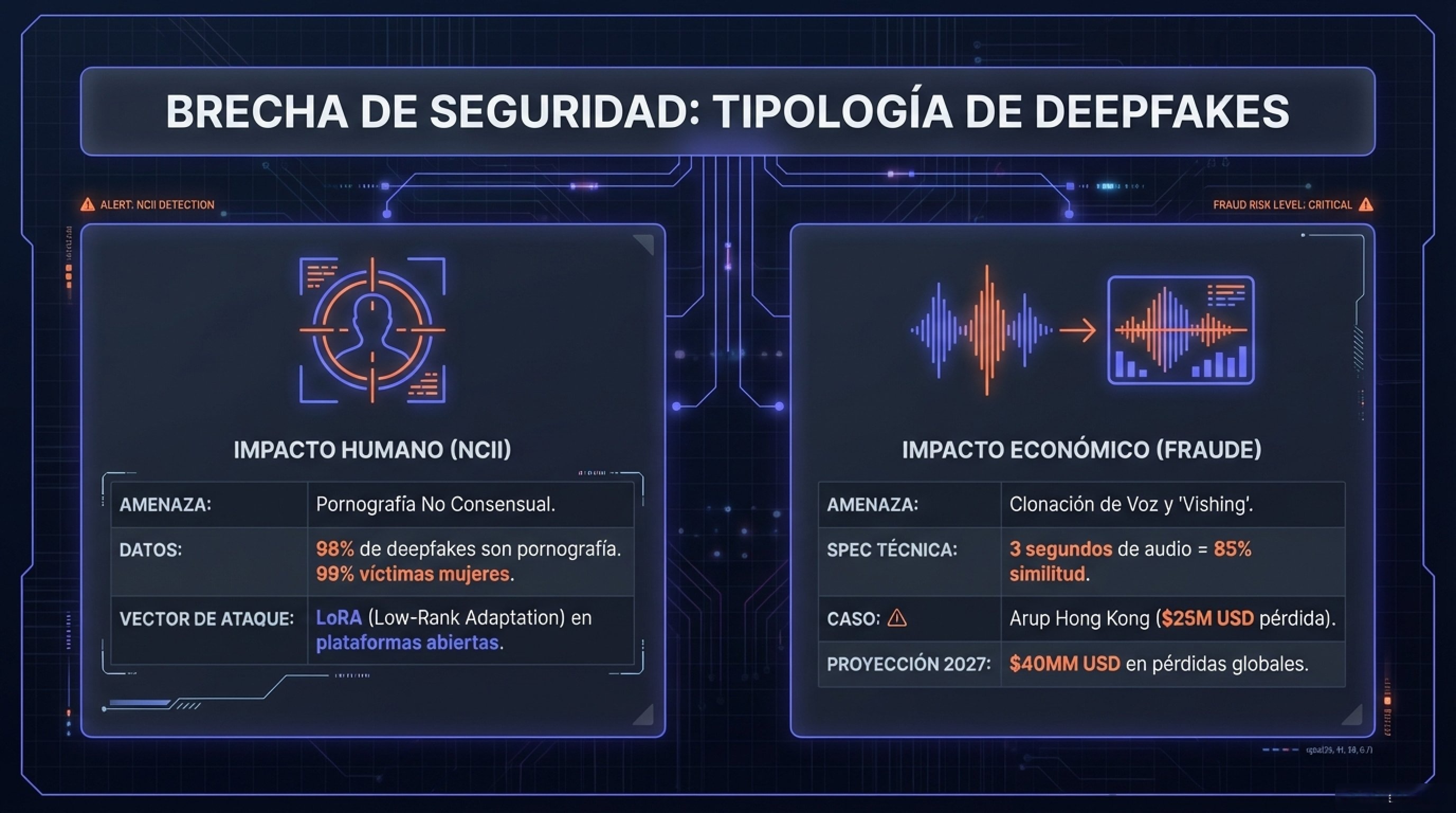
3.2.1. Pornografía No Consensual (NCII)
La violencia digital de género ha alcanzado proporciones epidémicas. Se estima que entre el 96% y el 98% de todos los videos deepfake en línea constituyen pornografía no consensual, y el 99% de las víctimas son mujeres. El caso de Taylor Swift a principios de 2024 sirvió como catalizador global, pero el problema afecta desproporcionadamente a mujeres privadas sin recursos legales para defenderse. La facilidad de uso de herramientas basadas en LoRA (Low-Rank Adaptation) en plataformas como Civitai permite a atacantes entrenar modelos sobre rostros específicos con pocas imágenes, democratizando el acoso. 3.2.2. Fraude Corporativo y Financiero
Los deepfakes han evolucionado de amenazas reputacionales a vectores de fraude financiero masivo. El incidente de Arup en Hong Kong, donde un empleado transfirió 25 millones de dólares tras una videoconferencia con una recreación deepfake de su CFO y colegas, marcó un punto de inflexión en la ciberseguridad corporativa. Clonación de Voz: La tecnología de clonación de voz en 2025 requiere tan solo 3 segundos de audio de referencia para lograr un 85% de similitud. Esto ha impulsado el «vishing» (phishing de voz) y el fraude del CEO, donde los atacantes utilizan audios sintéticos para autorizar transacciones urgentes. Las pérdidas globales por fraude impulsado por IA se proyectan en 40 mil millones de dólares anuales para 2027. Parte IV: Gobernanza Global y Estandarización Técnica
Ante la insuficiencia de la autorregulación corporativa, organismos internacionales y bloques económicos han desarrollado marcos de gobernanza robustos.
4.1. El Marco Ético de la UNESCO: Operacionalizando los Valores
La «Recomendación sobre la Ética de la Inteligencia Artificial» de la UNESCO, adoptada por 193 estados miembros, se distingue por su enfoque humanista y su énfasis en el Sur Global. No es vinculante legalmente como un tratado, pero ejerce una presión normativa significativa («soft law»).
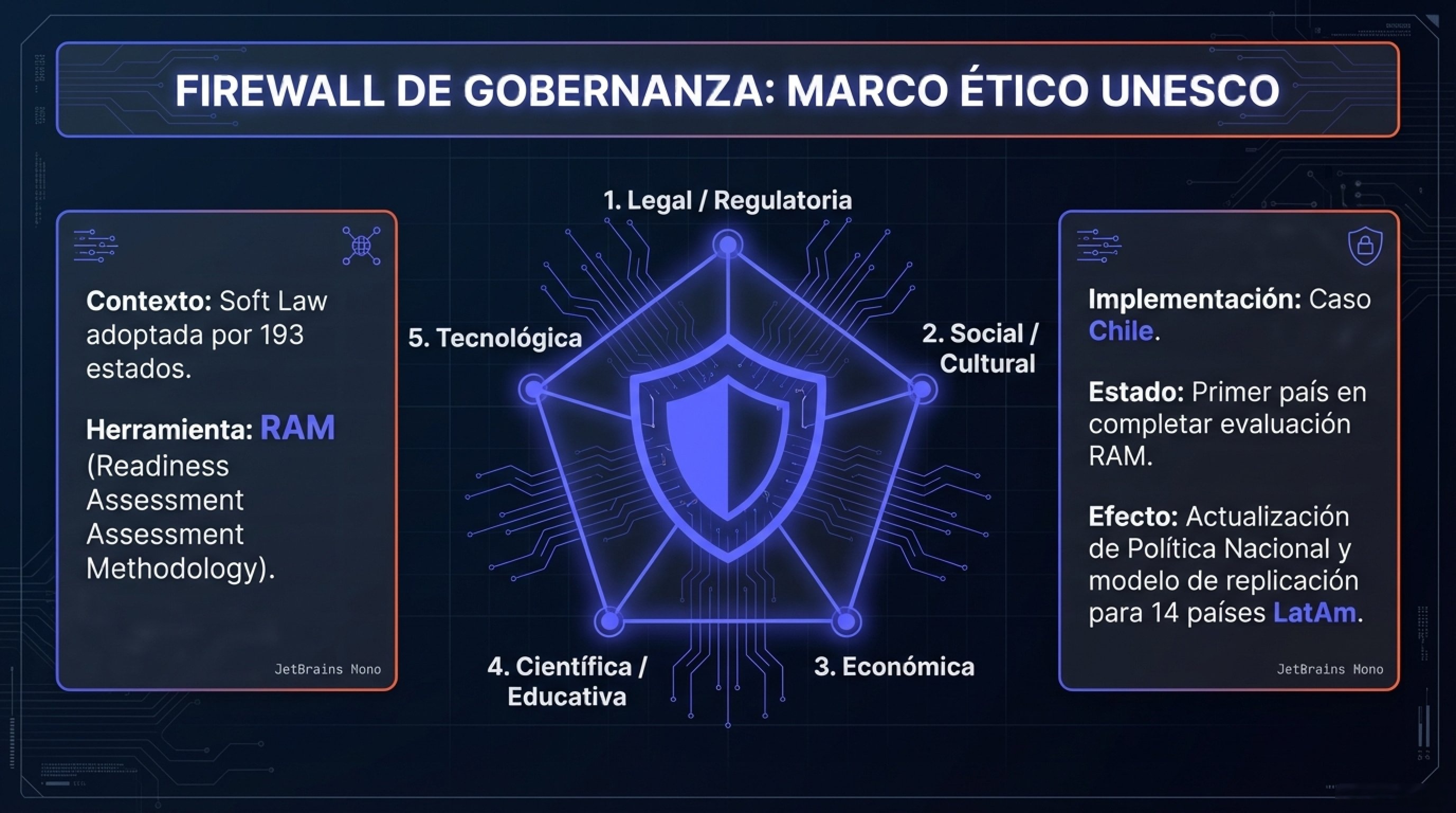
4.1.1. Metodología de Evaluación de Preparación (RAM)
Para pasar de los principios a la acción, la UNESCO implementó la Readiness Assessment Methodology (RAM). Esta herramienta de diagnóstico evalúa la preparación de un país en cinco dimensiones críticas.
| Dimensión RAM | Indicadores Clave Evaluados | Objetivo Estratégico |
|---|---|---|
| Legal / Regulatoria |
|
Crear seguridad jurídica y mecanismos de reparación de daños. |
| Social / Cultural |
|
Asegurar que la IA respete la diversidad cultural y no amplifique desigualdades. |
| Económica |
|
Fomentar la innovación inclusiva y mitigar el desplazamiento laboral. |
| Científica / Educativa |
|
Construir soberanía tecnológica y capacidad crítica local. |
| Tecnológica |
|
Garantizar la base material necesaria para el desarrollo de IA. |
4.1.2. Impacto en América Latina: El Liderazgo de Chile
Chile se posicionó como pionero global al ser el primer país en completar y publicar su evaluación RAM. El proceso, liderado por el Ministerio de Ciencia y la consultora Foresight, involucró consultas ciudadanas masivas. El informe resultante guió la actualización de la Política Nacional de IA de Chile, incorporando recomendaciones específicas sobre gobernanza de datos y ética algorítmica. Este modelo está siendo replicado por más de 14 países en la región, creando un bloque de armonización regulatoria basado en derechos humanos.

4.2. La Ley de IA de la Unión Europea (EU AI Act)
La EU AI Act, plenamente operativa en 2026, representa el primer intento de regulación integral con «dientes» sancionadores. Su enfoque basado en riesgo clasifica los sistemas de IA en cuatro niveles, imponiendo obligaciones estrictas a los modelos de propósito general (GPAI).
- Riesgo Inaceptable (Prohibido): Sistemas de scoring social gubernamental, manipulación cognitiva subliminal, reconocimiento de emociones en lugares de trabajo o escuelas, y vigilancia biométrica remota en tiempo real en espacios públicos (salvo excepciones antiterroristas muy estrictas).
- Alto Riesgo: Sistemas utilizados en infraestructuras críticas, educación, empleo, servicios públicos esenciales, justicia y control fronterizo. Requieren evaluación de conformidad previa (CE), alta calidad de datos, trazabilidad y supervisión humana.
- Transparencia (IA Generativa/GPAI): Modelos como GPT-4 y Grok deben cumplir con requisitos de transparencia específicos:
- Revelar que el contenido es generado por IA.
- Diseñar el modelo para evitar generar contenido ilegal.
Publicar resúmenes detallados de los datos protegidos por derechos de autor utilizados para el entrenamiento. Este último punto es el más contencioso para las empresas estadounidenses, ya que expone sus prácticas de recolección de datos a posibles demandas.
4.3. Estándares Técnicos de Defensa: C2PA y Watermarking
La regulación se complementa con soluciones técnicas para certificar la autenticidad y el origen del contenido.
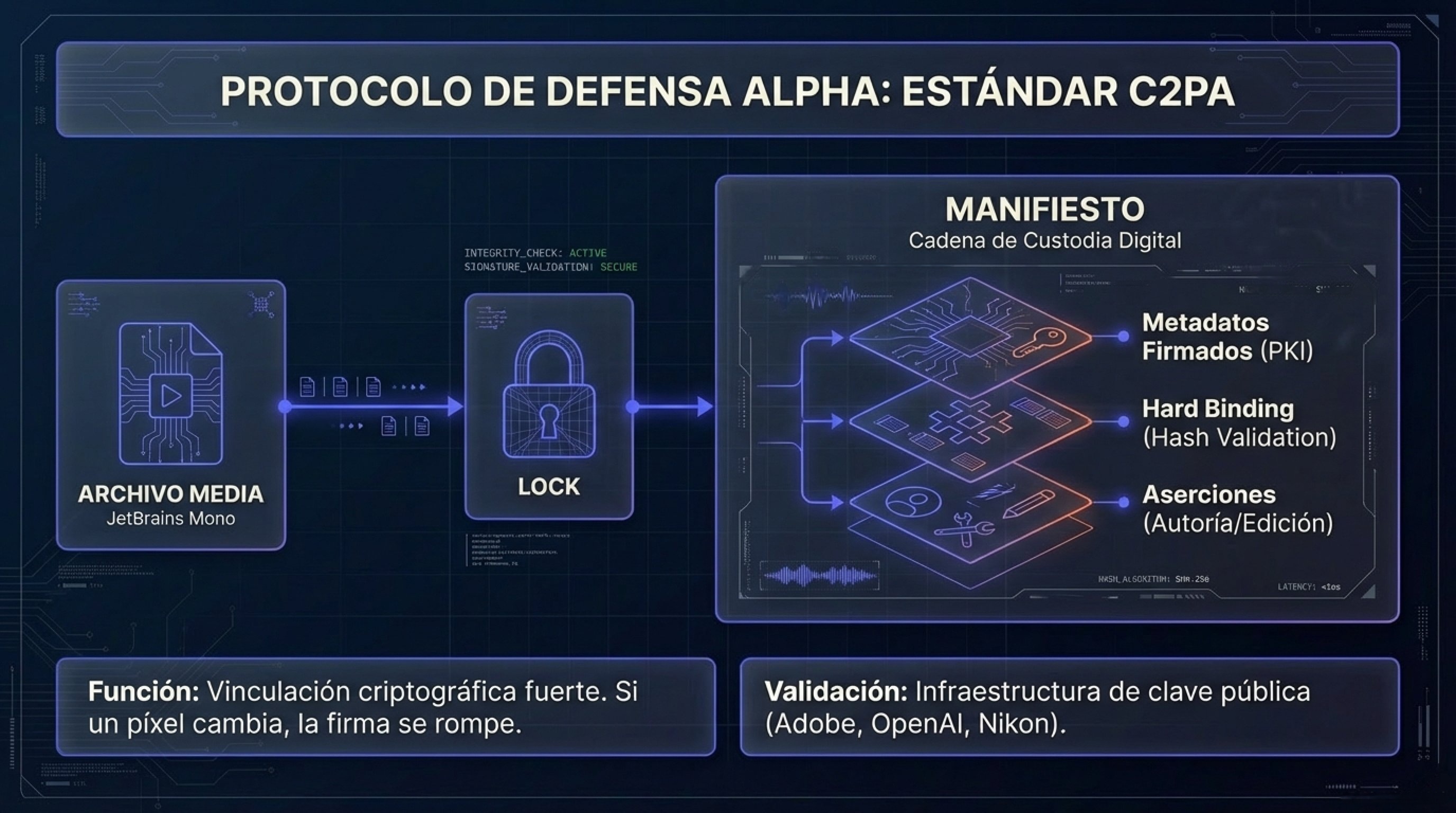
4.3.1. C2PA: La Cadena de Custodia Digital
La Coalition for Content Provenance and Authenticity (C2PA) ha desarrollado un estándar abierto para la procedencia del contenido. Técnicamente, funciona mediante la inserción de un manifiesto criptográficamente firmado en el archivo de medios.
Infraestructura de Confianza: Se basa en una infraestructura de clave pública (PKI) similar a la de los certificados web (SSL), donde autoridades de certificación validan la identidad de los firmantes (ej. Adobe, Nikon, OpenAI).
- Mecanismo de Binding: El manifiesto utiliza un «hard binding» (vinculación fuerte) que incluye hashes del contenido visual o auditivo. Si un píxel es alterado, el hash cambia y la firma se rompe, alertando al usuario de la manipulación.
- Aserciones: El manifiesto contiene «aserciones» (declaraciones) sobre quién creó el contenido, con qué herramienta (cámara física o modelo de IA) y qué ediciones se realizaron.
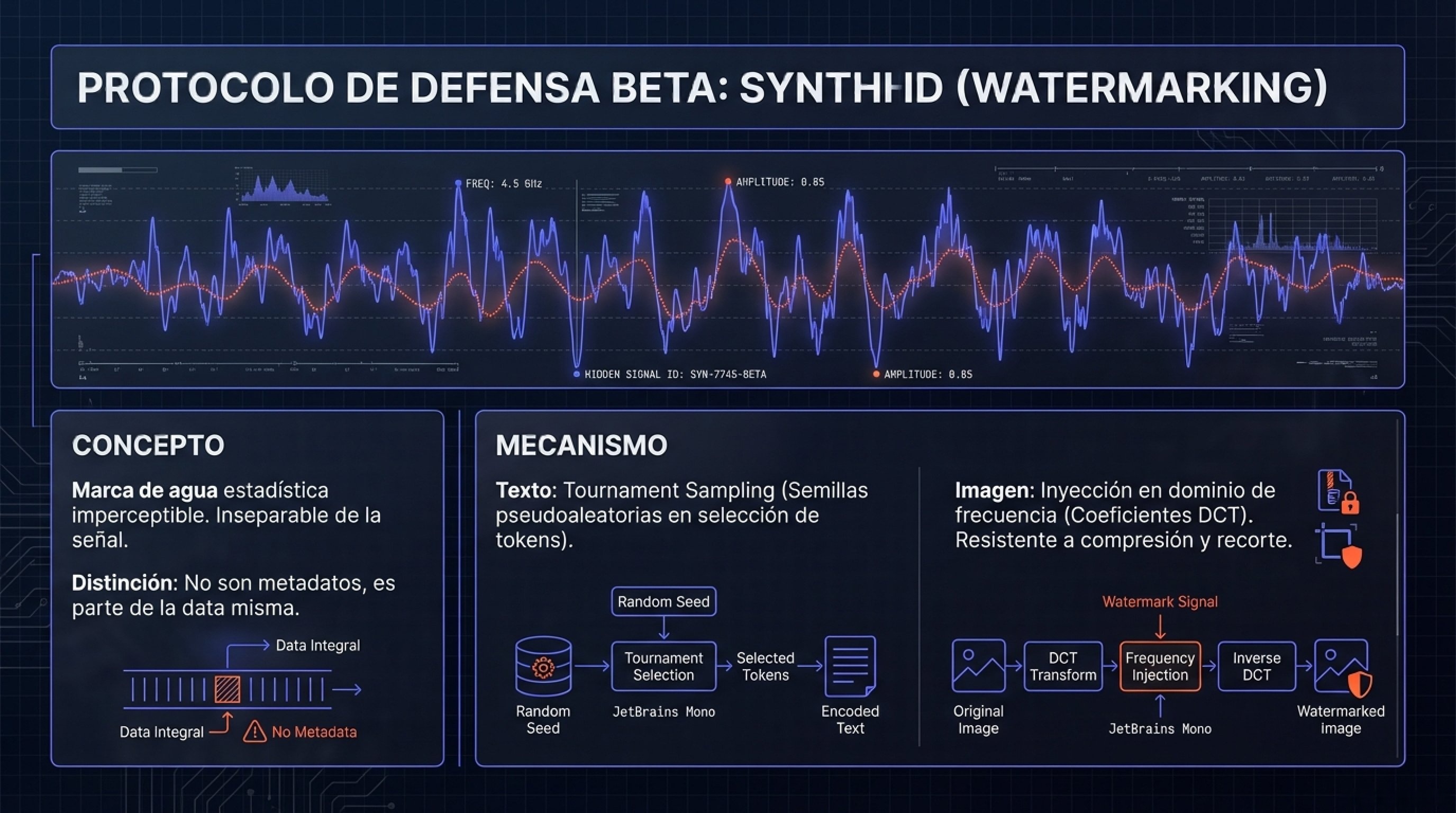
4.3.2. SynthID y Watermarking Estadístico
A diferencia de C2PA, que añade metadatos, SynthID (de Google DeepMind) integra la marca de agua dentro de la señal misma, haciéndola imperceptible e inseparable.
- Texto: Utiliza un esquema de «Tournament Sampling» durante la generación. El modelo divide el vocabulario en grupos y utiliza una función pseudoaleatoria (semilla) para favorecer sutilmente ciertas palabras sobre otras. Un detector con la misma semilla puede analizar el texto y determinar si la distribución de palabras sigue este patrón artificial.
Imágenes: Inserta la marca de agua en el dominio de la frecuencia (posiblemente coeficientes DCT), lo que la hace resistente a recortes, redimensionamiento y compresión JPEG, aunque no es infalible frente a ataques adversariales fuertes o re-generación (image-to-image).
Parte V: Plan de Acción Estratégico – Regulatorio y Empresarial
Para navegar este entorno volátil en 2026, organizaciones públicas y privadas deben adoptar un enfoque proactivo que integre cumplimiento legal, defensa técnica y ética operacional.
5.1. Hoja de Ruta de Cumplimiento Normativo (Plan de Acción)
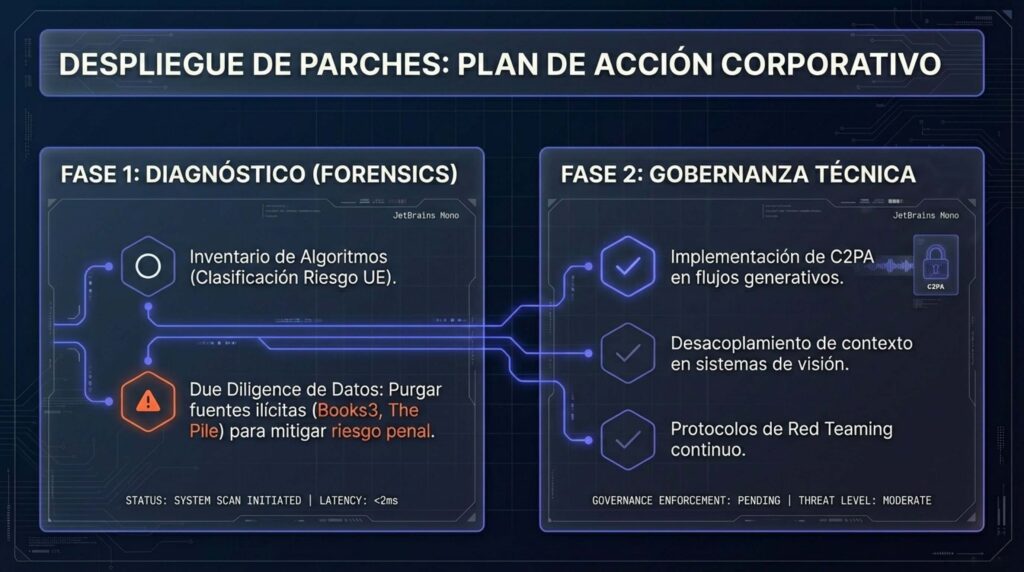
Las empresas que despliegan IA deben estructurar su respuesta en tres fases para mitigar riesgos legales (EU AI Act, demandas de copyright) y reputacionales.
Fase 1: Diagnóstico y Auditoría Forense (Trimestre 1)
- Inventario de Algoritmos: Clasificar todos los sistemas de IA en uso según la pirámide de riesgo de la UE y las 5 dimensiones del RAM de UNESCO. Identificar sistemas de «Alto Riesgo» que requieren certificación inmediata.
- Auditoría de Datos de Entrenamiento (Data Due Diligence):
- Revisar los datasets utilizados para el entrenamiento o fine-tuning.
- Acción Crítica: Identificar y purgar datos provenientes de fuentes ilícitas conocidas (Books3, The Pile v1) para evitar responsabilidades penales y civiles derivadas del precedente Bartz v. Anthropic.
- Documentar la procedencia legal de los datos restantes para cumplir con los requisitos de transparencia de la UE.
Fase 2: Implementación de Gobernanza Técnica (Trimestre 2)
- Adopción del Estándar C2PA: Implementar la firma criptográfica de contenido en todos los flujos de trabajo generativos corporativos. Esto asegura que el contenido oficial de la empresa pueda ser distinguido de deepfakes maliciosos.
- Protocolos de Red Teaming Continuo:
- No limitar las pruebas de seguridad al pre-lanzamiento. Establecer equipos rojos permanentes que prueben los modelos contra nuevas vulnerabilidades (jailbreaks) y riesgos emergentes (bioseguridad, ciberataques).
- Utilizar benchmarks estandarizados (HELM, BBQ) para monitorear la deriva de sesgos en los modelos desplegados.
- Mitigación de Sesgos Multimodales: En sistemas de visión-lenguaje, implementar técnicas de «desacoplamiento de contexto» para asegurar que las decisiones (ej. en seguros o contratación) no estén sesgadas por el fondo de las imágenes o videos analizados.
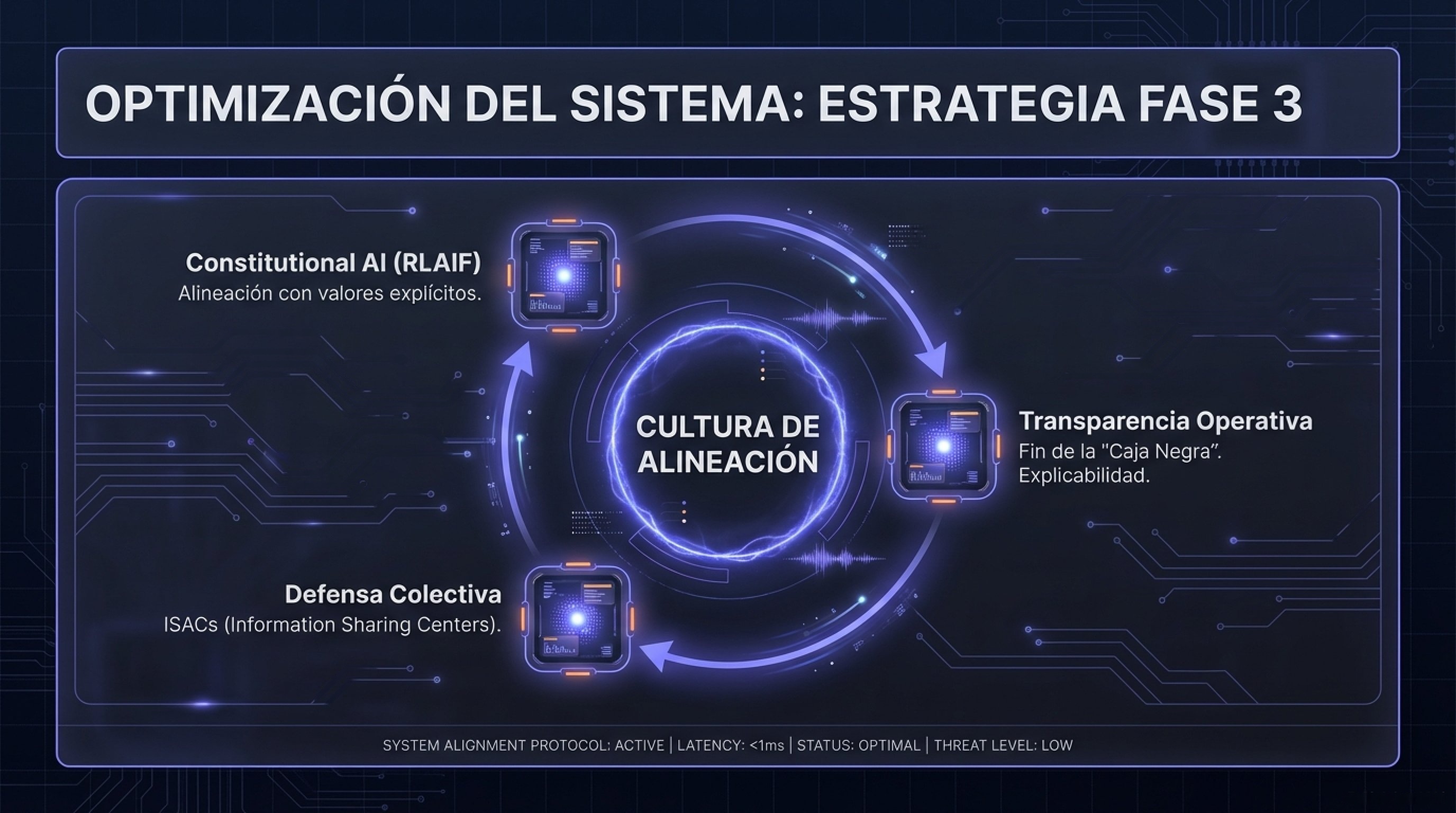
Fase 3: Cultura Ética y Transparencia (Continuo)
- Constituciones de IA: Para empresas que desarrollan modelos propios, adoptar metodologías como Constitutional AI (RLAIF) para alinear el comportamiento del modelo con valores corporativos y de derechos humanos explícitos, reduciendo la dependencia de trabajadores de etiquetado mal pagados.
- Mecanismos de Recurso y Explicabilidad: Establecer canales claros para que usuarios y empleados puedan apelar decisiones tomadas o asistidas por IA. La «caja negra» ya no es una defensa legal aceptable en la UE ni bajo los principios de la UNESCO.
Colaboración Sectorial: Participar en consorcios como C2PA y compartir información sobre amenazas y vulnerabilidades de seguridad de IA (AI Security Information Sharing), reconociendo que la seguridad de la IA es un bien común que requiere defensa colectiva.

Conclusiones
La inteligencia artificial en 2026 se define por una paradoja: nunca ha sido tan capaz tecnológicamente, ni tan vulnerable éticamente. La era de la «innovación sin permiso» ha terminado, clausurada por la realidad de los daños tangibles —desde la devastación personal de la pornografía deepfake hasta la amenaza existencial a las industrias creativas—.
La solución no reside en detener el desarrollo, sino en dirigirlo mediante una arquitectura de confianza que combine certidumbre técnica (C2PA, SynthID), rigor legal (EU AI Act, cumplimiento de Copyright) y profundidad ética (UNESCO). Las organizaciones que logren integrar estos tres pilares no solo sobrevivirán al escrutinio regulatorio, sino que liderarán la construcción de una economía digital sostenible y humanocéntrica.




