Eficiencia Algorítmica vs. Fuerza Bruta: La Ingeniería Detrás de Anthropic
Resumen Estructurado: La Ingeniería de Anthropic
El contexto: Un desglose técnico de cómo Anthropic logra competir en la frontera (SOTA) contra gigantes como Google y OpenAI teniendo solo una fracción de sus recursos de cómputo y capital humano.
Mientras la competencia apuesta por datasets masivos e indiscriminados, Anthropic prioriza la curación de datos («High Signal Density»). Entrenar con menos datos, pero de mayor calidad lógica, reduce drásticamente los FLOPs necesarios para la convergencia del modelo.
La clave de su eficiencia es Constitutional AI. Sustituyen el costoso y lento feedback humano (RLHF) por RLAIF (Feedback por IA). Esto permite escalar el alineamiento y la corrección de errores sin aumentar la plantilla de ingenieros linealmente.
- MoE (Mixture of Experts): Uso probable de arquitecturas dispersas para mantener costes de inferencia bajos con alta inteligencia.
- Prompt Caching: Reducción de costes del 90% para tareas repetitivas de gran contexto.
- Enfoque Utilitario: Renuncia a funciones «hype» (generación de vídeo/voz nativa temprana) para centrarse en razonamiento y código.
La estrategia de Anthropic demuestra que la eficiencia algorítmica y la limpieza de datos son defensas viables contra la ley de rendimientos decrecientes del hardware.
«En un mundo de fuerza bruta computacional, la eficiencia algorítmica es la única ventaja competitiva sostenible a largo plazo.»
En una industria obsesionada con el tamaño de los clústeres de GPUs y la inversión multimillonaria, Daniela Amodei, cofundadora de Anthropic, ha lanzado un mensaje que resuena más en los laboratorios de ingeniería que en las salas de marketing: no se trata de cuánto tienes, sino de cómo lo usas.
Mientras OpenAI y Google compiten en una carrera armamentística de hardware, Anthropic ha logrado mantener a sus modelos Claude en la cima de los benchmarks (como LMSYS Chatbot Arena) con una fracción de los recursos humanos y computacionales de sus rivales. ¿Cómo es esto posible técnicamente? La respuesta no es magia, es una optimización radical de la arquitectura y los datos.
Este artículo disecciona la estrategia de «densidad de talento y cómputo» que permite a una empresa con menos recursos desafiar la ley de los rendimientos decrecientes.
El Mito de la Escala Infinita
Durante años, la IA se ha regido por una interpretación simplista de las Leyes de Escala de Kaplan (2020): aumentar el cómputo, el tamaño del dataset y los parámetros mejora el rendimiento de forma predecible. Sin embargo, esta aproximación de «fuerza bruta» tiene un límite: el coste marginal de mejora se dispara.
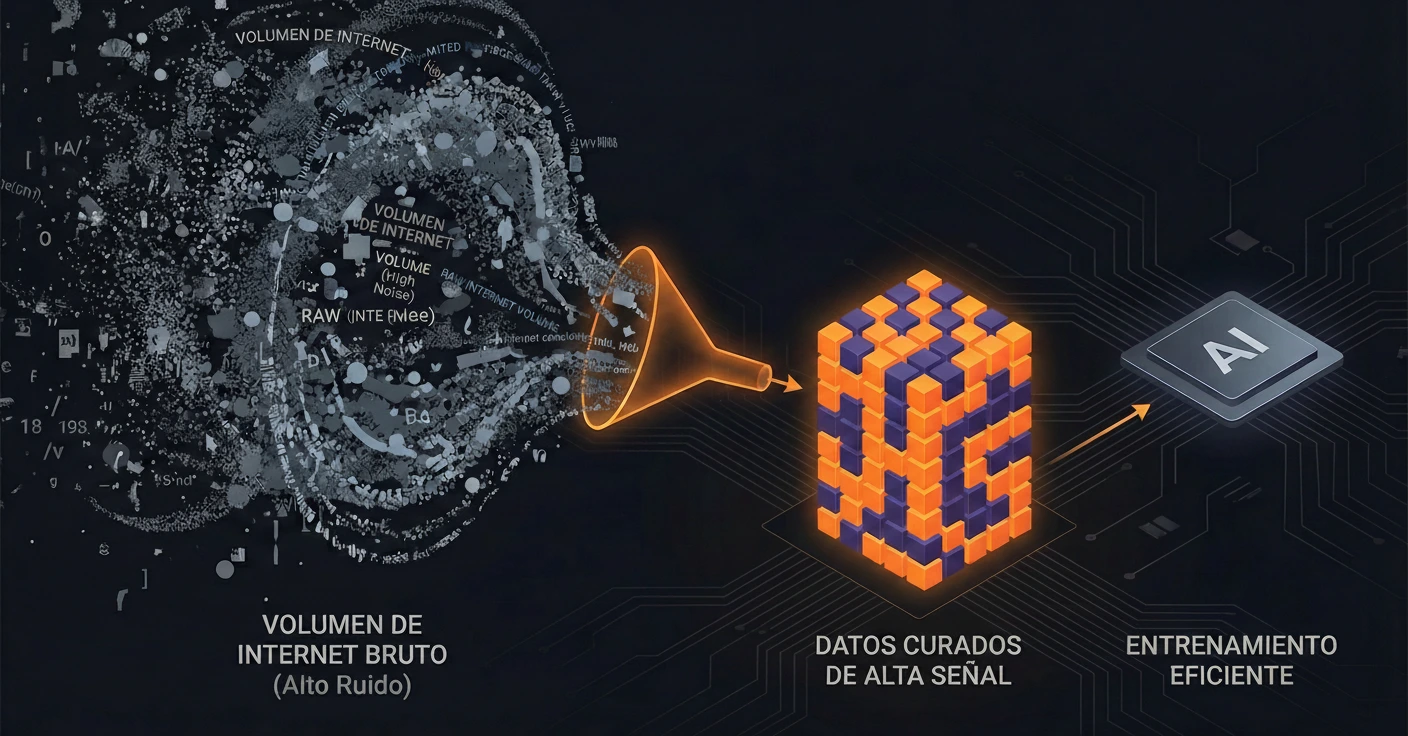
Anthropic ha apostado por una vía alternativa: la calidad sobre la cantidad. En lugar de alimentar al modelo con todo internet (incluyendo ruido y basura), se centran en la curación quirúrgica de datasets.
Densidad de Datos vs. Volumen de Datos
Bajo el capó, entrenar con menos datos pero de mayor calidad (libros de texto, código verificado, papers científicos) reduce drásticamente los FLOPs (operaciones de coma flotante) necesarios para alcanzar la convergencia. Un modelo entrenado con «tokens de alta señal» aprende patrones de razonamiento más rápido que uno que debe filtrar el ruido de foros de internet de baja calidad.
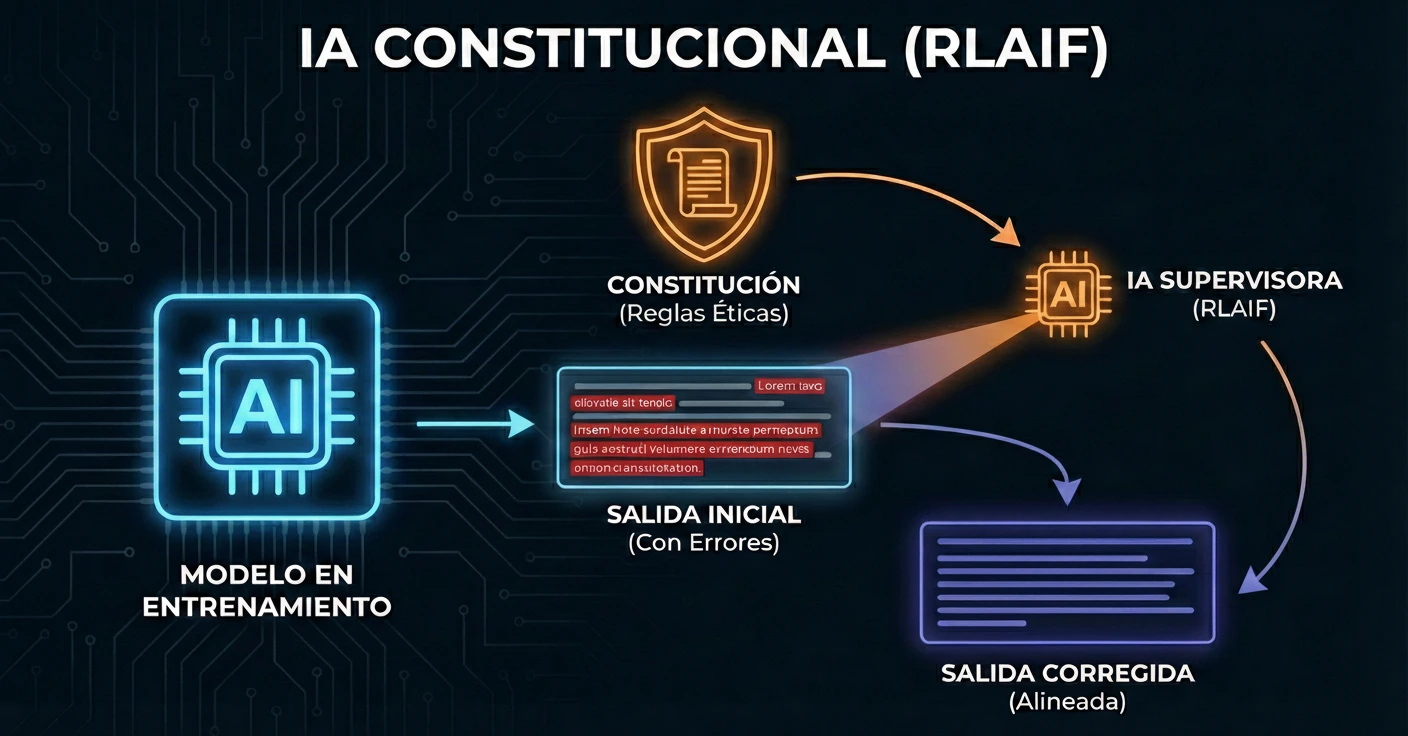
Constitutional AI: La Automatización de la Alineación
El mayor cuello de botella (y coste) en el desarrollo de LLMs modernos es el RLHF (Reinforcement Learning from Human Feedback). Contratar ejércitos de humanos para puntuar respuestas es lento, caro y propenso a errores.
Anthropic implementa RLAIF (Reinforcement Learning from AI Feedback), englobado en su técnica Constitutional AI.
- Constitución: Se define un conjunto de principios lógicos y éticos (la «Constitución»).
- Crítica y Revisión (SFT): El modelo genera respuestas, se critica a sí mismo basándose en la constitución y refina su propia salida. Esto es Supervised Fine-Tuning sin intervención humana directa.
- Preferencia por IA: Un modelo de IA evalúa dos respuestas y decide cuál se ajusta mejor a la constitución.
Resultado Técnico: Se elimina la dependencia lineal de la mano de obra humana. El proceso de alineación se vuelve escalable computacionalmente, permitiendo iteraciones mucho más rápidas y baratas que las de sus competidores.
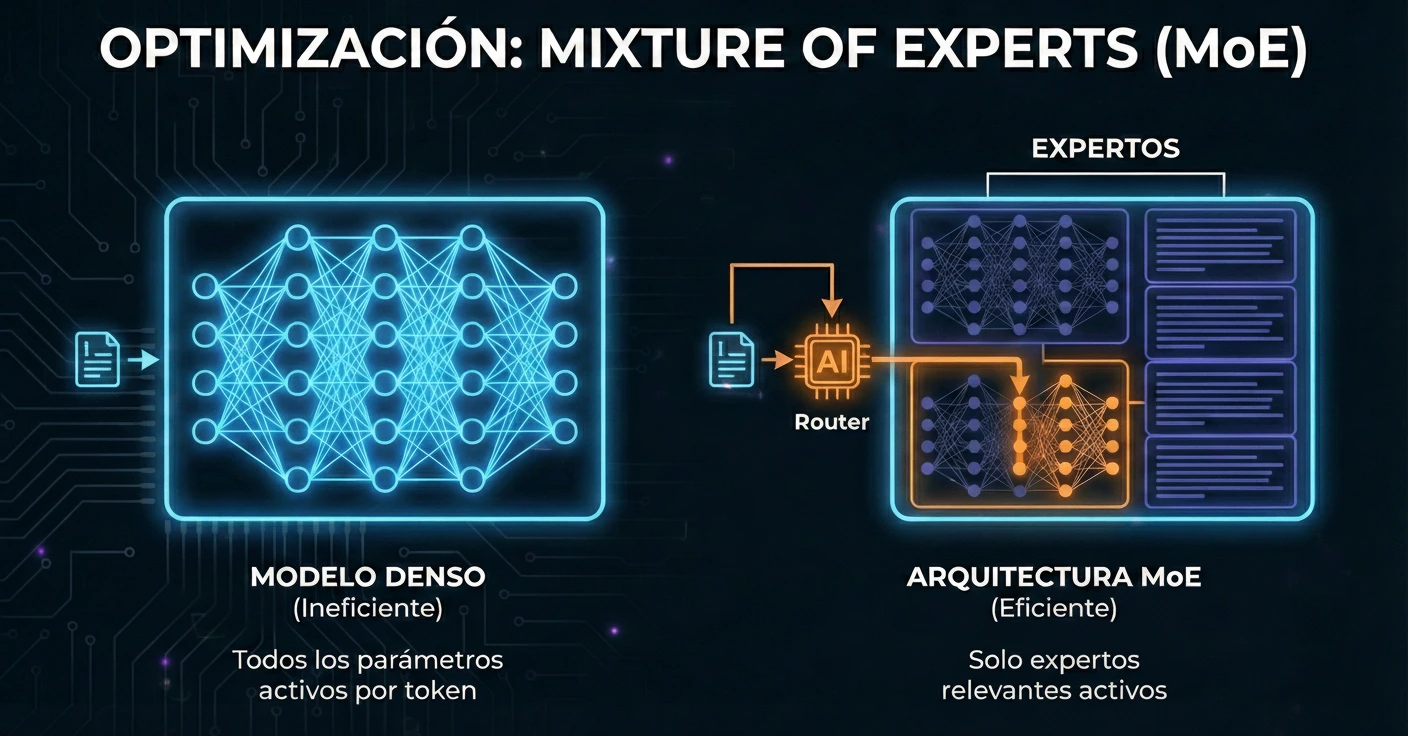
Arquitectura Probable: Mixture of Experts (MoE)
Aunque Anthropic es reservada con sus pesos, el comportamiento de inferencia de Claude 3.5 Sonnet sugiere un uso altamente eficiente de arquitecturas Sparse Mixture of Experts (MoE).
En un modelo denso tradicional (como GPT-3), cada token generado activa todos los parámetros de la red. Esto es computacionalmente ruinoso. En una arquitectura MoE, el modelo se divide en sub-redes especializadas («expertos»). Un «router» decide qué expertos (solo una fracción del total) se activan para procesar un token específico.
- Ventaja: Permite tener un modelo con un número masivo de parámetros totales (capacidad de conocimiento) pero con un coste de inferencia equivalente a un modelo mucho más pequeño.
- Eficiencia: Esto explica cómo Claude puede ofrecer razonamiento profundo sin la latencia o el coste operativo que requeriría un modelo denso de igual capacidad.
Casos de Uso Reales: La Ventaja de la Eficiencia
La filosofía de «hacer más con menos» de Anthropic tiene aplicaciones directas para desarrolladores y empresas que no pueden permitirse entrenar sus propios modelos base.
1. Prompt Caching para Reducción de Costes
Anthropic introdujo el Prompt Caching mucho antes de que fuera estándar. Para aplicaciones que envían contextos largos repetitivos (ej: bases de código enteras o documentos legales), esto reduce el coste de entrada en un 90% y la latencia en un 85%.
- Caso Real: Un asistente de programación que analiza un repositorio de 50 archivos en cada consulta. Sin caché, re-procesar los 50 archivos cuesta dinero y tiempo en cada turn. Con caché, solo se procesan los cambios, haciendo viable el «chat con tu repo».
2. Destilación de Modelos (Haiku)
La eficiencia permite crear modelos destilados (como Claude Haiku) que son extremadamente rápidos y baratos, ideales para tareas de clasificación masiva o extracción de datos donde usar un modelo «frontera» (como Opus) sería un desperdicio de recursos.
Aprende: Optimización de Contexto
Si quieres aplicar la filosofía de eficiencia de Anthropic en tus propios flujos de trabajo con LLMs, céntrate en la relación Señal/Ruido de tus prompts.
No inyectes documentos enteros si no es necesario. Usa scripts de pre-procesamiento para limpiar la información antes de enviarla al modelo.
Análisis Crítico: Las Limitaciones de la Frugalidad
No todo es positivo. La estrategia de Anthropic tiene costes ocultos. Al operar con menos recursos («a fraction of what they have», según Amodei), Anthropic a menudo llega más tarde a las funcionalidades multimodales.
Mientras OpenAI lanzaba el modo de voz avanzado y generación de vídeo (Sora), Anthropic seguía perfeccionando el texto y el código. Su enfoque es puramente utilitario («herramientas para el trabajo»), lo que les resta atractivo en el mercado de consumo masivo, aunque fideliza al sector profesional. Además, depender de la eficiencia algorítmica implica que cualquier avance en hardware por parte de la competencia (que tiene más dinero para comprarlo) podría volver a abrir la brecha si Anthropic no innova constantemente en software.
Glosario Técnico: Eficiencia en IA
No te pierdas...
La anarquía soberana de OpenClaw y el precio del caos digital
Resumen Estructurado: El Fenómeno OpenClaw El contexto: OpenClaw ha democratizado los agentes de IA locales (ejecutados en tu propio hardware), pero su crecimiento viral ha expuesto graves fallos de seguridad y conflictos de marca, convirtiéndose en el estándar «de facto» pero inseguro. 1. Crisis de Identidad Nació como Clawdbot (bloqueado legalmente por Anthropic), mutó a…
Kimi k2.5, la Inteligencia Agéntica Visual que Jubila al Modelo Secuencial
Resumen Estructurado: La Revolución Kimi k2.5 El contexto: Moonshot AI lanza Kimi k2.5, un modelo nativamente multimodal (15T tokens) que rompe el paradigma del «agente único» mediante enjambres colaborativos y visión profunda. 1. «Coding with Vision» El modelo no solo describe imágenes; entiende flujos de vídeo. Puedes grabar una interacción web y Kimi generará el…
OpenAI Prism: Qué es y cómo funciona el nuevo editor científico gratuito con GPT-5.2
Resumen Estructurado: La Revolución Prism El contexto: El lanzamiento de OpenAI Prism (Enero 2026) marca el fin de la era de «herramientas desconectadas» en la ciencia. Se abandona la fricción de Word/LaTeX manual en favor de un entorno unificado. 1. Arquitectura «Crixet» + GPT-5.2 Prism no es un chat, sino un editor completo construido sobre…
Estrategia de OpenAI con GPT-5.4 frente a Google y Anthropic
Resumen estructurado: La estrategia de OpenAI La guerra de ecosistemas. La avalancha de lanzamientos de la familia GPT-5 no es casualidad; responde a una táctica corporativa para frenar la pérdida masiva de usuarios y dominar el entorno de trabajo del usuario frente a sus competidores. 1. El detonante militar OpenAI ha asumido contratos de defensa…
El Pentágono usa a Claude en Irán desafiando el veto de Trump
Resumen estructurado El motín de Claude El incidente El Comando Central de EE.UU. utilizó el modelo Claude de Anthropic para identificar objetivos y realizar simulaciones durante ataques en Irán, ignorando una prohibición federal emitida horas antes. 1. El lock-in tecnológico Claude es actualmente el sistema de IA de frontera integrado en las redes de inteligencia…
Shadow AI: Los riesgos de usar IA «en secreto» en tu empresa y cómo protegerte
Resumen Ejecutivo: Shadow AI 2026 El Contexto: La eficiencia operativa impulsa a los empleados a usar IA no sancionada, exponiendo datos críticos y creando una red de «Shadow Agents» autónomos imposibles de auditar. 1. El Riesgo (Vibe Coding & Coste) El uso de cuentas gratuitas y código generado sin supervisión («Vibe Coding») dispara el coste…