
Demanda contra OpenAI por fuga de datos hacia Meta y Google
Resumen estructurado sobre la demanda contra OpenAI por fuga de datos
El contexto ambiental: Una demanda colectiva en el estado de California acusa formalmente a OpenAI de vulnerar el derecho a la intimidad y las leyes de escuchas telefónicas. La acusación revela la presencia de rastreadores analíticos de terceros integrados directamente en la interfaz del chatbot, comprometiendo la confidencialidad esperada por los usuarios.
Debido al funcionamiento de la plataforma como una aplicación de página única, los cambios en el historial conversacional mutan el DOM para generar los títulos laterales del menú. Los scripts de analítica web externa capturan estas variaciones textuales y las empaquetan en plano junto con metadatos de comportamiento, enviándolas en tiempo real hacia servidores de terceros.
El peligro real de este flujo radica en la capacidad de cruce algorítmico de las redes publicitarias. Al recibir las cadenas de texto del prompt, estas corporaciones las indexan junto con las cookies de seguimiento activas y los inicios de sesión en plataformas sociales, asociando datos médicos o corporativos confidenciales a identidades civiles concretas.
Ante la falta de filtros de aislamiento nativos, los profesionales deben tomar el control de su infraestructura local. Inspeccionar el tráfico saliente desde la pestaña de red de las herramientas de desarrollo e implementar bloqueadores estrictos de scripts o resoluciones DNS de sumidero detiene la fuga de información de forma inmediata.
Tratar las interacciones íntimas con modelos de lenguaje como eventos ordinarios de monetización publicitaria es un error técnico insostenible. La viabilidad de la industria requiere establecer un marco de secreto profesional absoluto e inalterable en las interfaces.
«La soberanía sobre los datos no es una opción de configuración avanzada, es el cimiento de la confianza en los sistemas autónomos.»
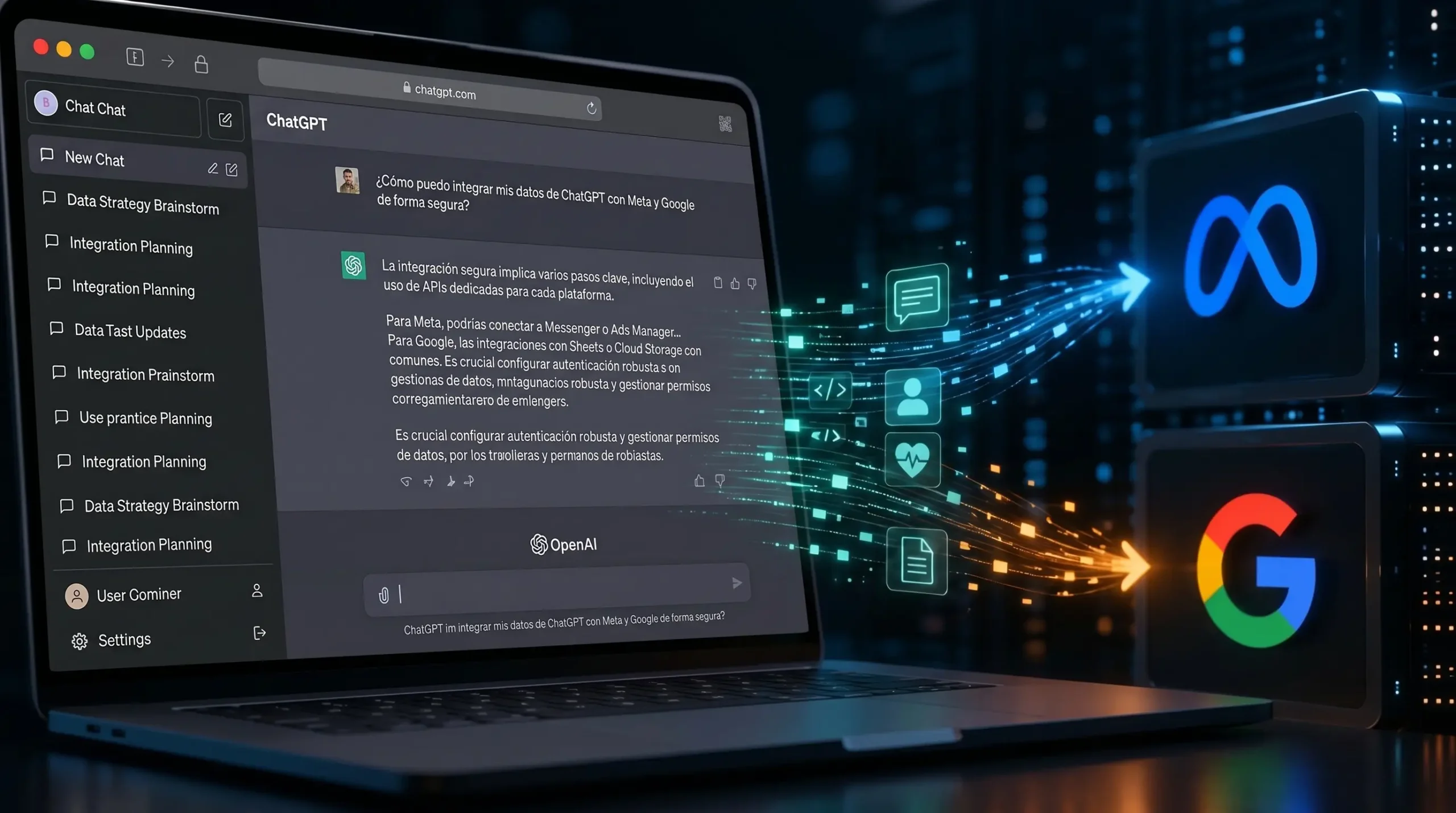
La reciente demanda colectiva presentada en un tribunal federal de California contra OpenAI pone de manifiesto una vulnerabilidad crítica en la infraestructura de privacidad de las interfaces conversacionales. El conflicto legal, impulsado por Amargo Couture durante este mes de mayo de 2026, no cuestiona los pesos del modelo de lenguaje ni el entrenamiento algorítmico, sino una negligencia directa en la arquitectura web de la plataforma. La acusación detalla que el sitio web tiene integrados códigos de seguimiento de terceros, concretamente Meta Pixel y Google Analytics, los cuales interceptan y transmiten información altamente sensible de los usuarios a estas redes publicitarias, vulnerando leyes de privacidad federales y estatales al operar como una escucha no autorizada.
Arquitectura y funcionamiento del rastreo web en inteligencia artificial
El núcleo técnico de esta brecha de privacidad reside en la forma en que los scripts de analítica interactúan con las aplicaciones web modernas. La interfaz del chatbot funciona como una aplicación de página única que actualiza dinámicamente el modelo de objetos del documento y el historial del navegador sin recargar la web por completo. Cuando un usuario introduce un prompt, el sistema genera automáticamente un título para esa conversación basado en la temática central de la consulta para organizar el historial lateral.
Los rastreadores insertados por los equipos de marketing están diseñados para capturar cualquier mutación del título de la página, los cambios en las rutas de navegación y los eventos de interacción del usuario. Al inyectar estos scripts en su interfaz principal, la empresa permite que cada vez que un chat se titula con el resumen de la inquietud del usuario, ese fragmento de texto se empaquete en una petición de red. Esta carga útil viaja en tiempo real hacia los servidores de Meta y Google, transmitiendo el contexto exacto de lo que el usuario está debatiendo con la inteligencia artificial sin ningún filtro de anonimización previo.
Anatomía de la fuga de datos en interfaces de IA
Mapeo estructural de la vulnerabilidad de privacidad expuesta en el flujo de interceptación del historial de chats.
| Vía del flujo | Mecanismo técnico | Datos comprometidos | Riesgo |
|---|---|---|---|
| Origen (SPA) | Mutación dinámica del DOM durante la renderización lateral del historial. | Títulos autogenerados basados en prompts de alto contexto (código propietario, salud, finanzas). | Localizado |
| Interceptación | Scripts de seguimiento externo capturan eventos de ruta y volcados del document.title. | Cadenas de texto en plano empaquetadas junto a metadatos de comportamiento e identificadores únicos web. | Fuga |
| Ad Networks | Cruce algorítmico en servidores de terceros mediante cookies persistentes y sesiones activas. | Desanonimización absoluta. Vinculación directa de la consulta profesional/médica con la identidad real del usuario. | Crítico |
Casos de uso reales y el riesgo de la desanonimización
La gravedad de esta fuga de datos se amplifica exponencialmente por la naturaleza del uso que los profesionales y ciudadanos dan a los modelos fundacionales en la actualidad. A diferencia de un motor de búsqueda tradicional, la interacción con un agente conversacional asume un grado de confidencialidad e intimidad muchísimo mayor. Un desarrollador puede pegar fragmentos de código propietario para su depuración, un paciente puede describir síntomas médicos detallados para entender un diagnóstico preliminar, o un directivo puede resumir documentos financieros críticos antes de una junta.
Cuando estos resúmenes conversacionales llegan a los servidores de empresas de publicidad, el riesgo de desanonimización es inminente. Estas plataformas cruzan los datos entrantes con las cookies activas, las huellas digitales del dispositivo y las sesiones iniciadas en sus respectivos ecosistemas. El resultado es que una consulta médica íntima o una crisis financiera confidencial queda vinculada directamente a la identidad real del usuario en su perfil social, alimentando algoritmos de hiperpersonalización para la venta de anuncios. Para ilustrar mejor este proceso de extracción, más adelante crearemos un diagrama de flujo abstracto que represente esta fuga de datos entre el usuario, la interfaz y los servidores de terceros.
Semáforo del prompt seguro
Una guía visual para clasificar la información antes de compartirla con modelos de lenguaje comerciales en tu entorno profesional o educativo.
Datos confidenciales y secretos
Información médica de alumnos o pacientes, balances financieros no publicados, código fuente interno, contraseñas o estrategias de negocio que otorgan ventaja competitiva.
Información corporativa interna
Borradores de correos electrónicos dirigidos a proveedores, actas de reuniones departamentales, reportes de rendimiento o documentación de proyectos en fase de desarrollo.
Conocimiento público genérico
Generación de lluvia de ideas (brainstorming), creación de temarios estándar, traducciones de textos públicos, búsqueda de sinónimos o redacción creativa sin contexto privado.
Aprende a auditar y bloquear rastreadores en asistentes web
Frente a la adopción masiva de agentes autónomos, es imperativo que los usuarios asuman el control de su soberanía digital auditando el tráfico de red de las herramientas que utilizan en su día a día. Cualquier profesional puede inspeccionar estas fugas abriendo las herramientas de desarrollo de su navegador y navegando a la pestaña de red. Al interactuar con el chatbot y observar el tráfico, es posible filtrar las peticiones salientes y buscar dominios de rastreo conocidos para comprobar si se está filtrando texto en plano o codificado dentro de las cargas útiles.
Para mitigar este riesgo de forma proactiva, la implementación de filtrado a nivel de sistema de nombres de dominio resulta la medida más eficaz. Configurar redes privadas con sumideros de dominios o utilizar extensiones de navegador estrictas que bloqueen la ejecución de scripts no esenciales garantiza que la interacción con el modelo de lenguaje se mantenga contenida de forma hermética. Al bloquear las peticiones a los servidores de analítica, se asegura que el flujo de datos permanezca estrictamente entre el dispositivo local y los servidores principales del proveedor de inteligencia artificial.
Análisis ético sobre la privacidad en la era de los modelos fundacionales
Este incidente evidencia una profunda contradicción en el desarrollo de la industria tecnológica. Por un lado, se diseñan agentes autónomos concebidos para actuar como asistentes personales, íntimos y omnipresentes, mientras que, por otro lado, se les aplica la misma arquitectura de extracción de datos masiva propia de las redes sociales de la década pasada. Tratar las consultas a una inteligencia artificial avanzada como simples eventos de tráfico web para engordar la monetización publicitaria es un error de diseño estructural inaceptable.
La privacidad por diseño debe dejar de ser una simple recomendación académica para convertirse en un estándar técnico innegociable. La confianza en los modelos fundacionales depende de que los usuarios tengan la certeza matemática de que sus prompts gozan del mismo nivel de secreto profesional que una consulta legal. El debate que abre esta demanda no solo definirá las futuras sanciones económicas para las grandes tecnológicas, sino que sentará la base de la jurisprudencia técnica sobre los derechos digitales de los ciudadanos frente a los ecosistemas de inteligencia artificial.
Fuentes verificadas
- Análisis de ingeniería algorítmica y optimización profunda del feed profesional
- Estudio analítico de cambios estructurales y visibilidad en el ecosistema B2B
- Auditoría masiva de datos sobre retención de usuarios basada en millones de publicaciones
- Métricas de referencia e indicadores clave de rendimiento orgánico en redes profesionales




