Evolución y nuevas capacidades generativas en Google Vids
Resumen técnico de Google Vids
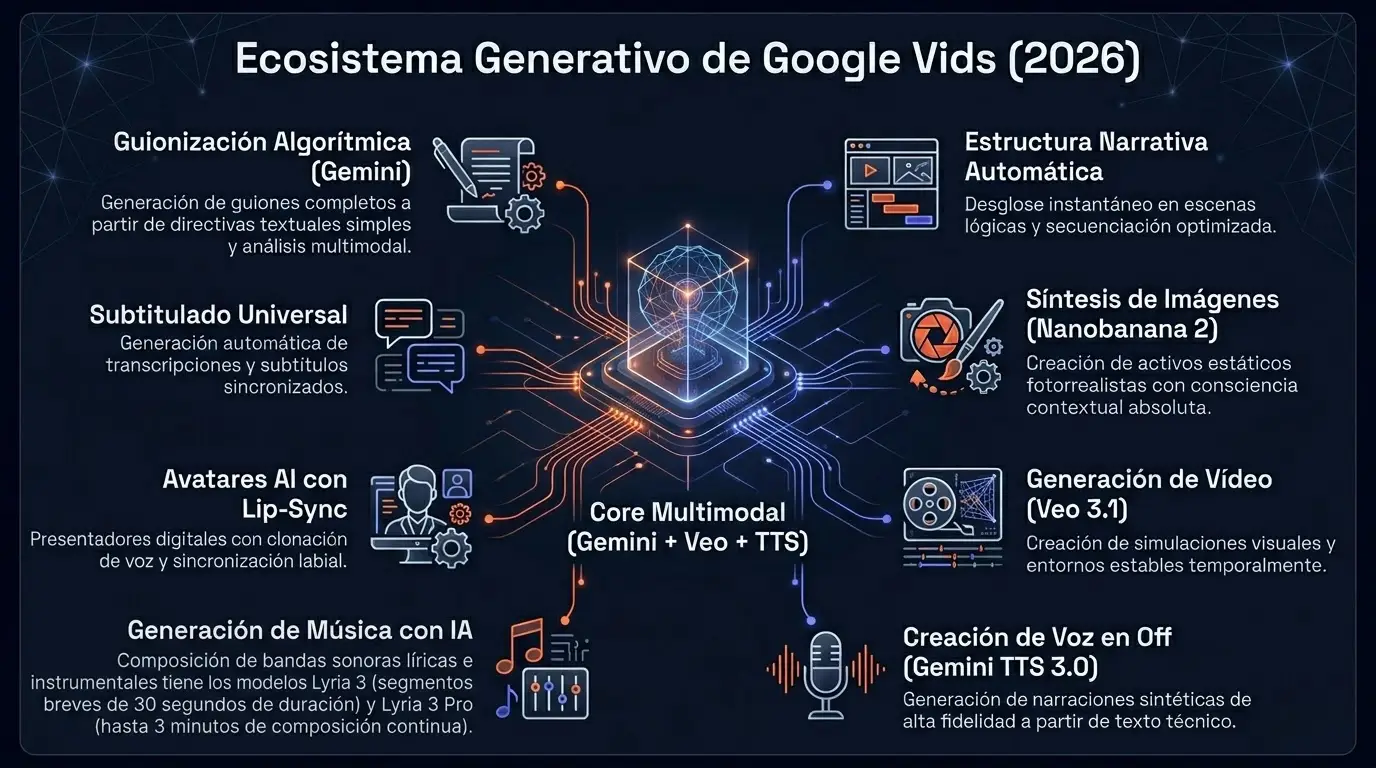
El contexto: Google Vids transforma la edición tradicional en una arquitectura de generación concurrente donde la inteligencia artificial asume el rol de renderizador visual, sonoro y estructural dentro del ecosistema corporativo.
Fusión del motor fundacional Veo 3.1 para simulaciones físicas estables temporalmente, con Gemini para la asimilación de documentos y guionización algorítmica. Los activos estáticos se delegan en Nanobanana 2 para preservar una coherencia estética absoluta.
- Síntesis vocal: Locuciones generadas mediante Gemini TTS 3.0 con soporte nativo de subtitulado universal.
- Música generativa: Pistas acústicas de 30 segundos con Lyria 3 y composiciones extendidas con Lyria 3 Pro, regidas por algoritmos de atenuación inteligente frente a la voz.
- Presentadores sintéticos: Avatares multilingües con clonación vocal y sincronización labial (Lip-Sync).
El estrato gratuito permite la renderización de vídeo y generación de voz sin consumir créditos de Google Flow, democratizando el acceso base. La suscripción Pro desbloquea los conductos de alta carga computacional, permitiendo la instanciación de avatares sintéticos y la orquestación musical con los modelos Lyria.
La ineficiencia sistémica de la postproducción fragmentada queda anulada. La plataforma establece un estándar donde la redacción de directivas técnicas sustituye a la manipulación manual de fotogramas o licencias, escalando la comunicación corporativa a un nivel de eficiencia inédito.
El entorno corporativo e institucional contemporáneo ha experimentado una transición innegable hacia el consumo de información audiovisual, relegando progresivamente los manuales de texto estáticos y las presentaciones de diapositivas tradicionales a un segundo plano. En respuesta a esta demanda de una comunicación más dinámica, eficiente y escalable, Google introdujo Google Vids. Anunciado inicialmente en la conferencia Google Next de 2024 en fase alfa y posteriormente estandarizado como una aplicación predeterminada para todas las cuentas de Google Workspace y Gmail, Vids representa un cambio de paradigma en la democratización de la edición de vídeo. Esta plataforma no pretende competir con los editores de vídeo no lineal de grado cinematográfico, sino que se posiciona como una herramienta de creación impulsada por inteligencia artificial diseñada específicamente para el trabajo colaborativo, la formación interna, las demostraciones de productos y el marketing de respuesta rápida.
Arquitectura de la interfaz y la línea de tiempo basada en escenas
Bajo el capó, Google Vids opera con una estructura topológica que difiere radicalmente de los editores profesionales tradicionales. En lugar de una secuencia de pistas infinitas y concurrentes, el motor implementa una línea de tiempo discretizada en contenedores lógicos denominados escenas. Esta decisión de diseño reduce drásticamente la carga cognitiva del usuario, permitiendo entender cada bloque como una diapositiva dinámica con una duración temporal elástica que puede configurarse desde el panel lateral. Dentro del lienzo principal, los elementos se organizan visualmente mediante un sistema estricto de índice Z para controlar la profundidad. Para dotar al sistema de inteligencia desde el primer clic, el entorno ofrece la función de preproducción asistida impulsada por el modelo Gemini, la cual permite invocar comandos multimodales vinculando documentos complejos de Google Drive mediante el símbolo de arroba. Al procesar estos documentos, la red neuronal genera un storyboard completo que el operador puede validar antes de comprometer recursos.
Generación de imágenes con Nanobanana 2
La orquestación de la comunicación audiovisual en Google Vids no se limita a la secuenciación de material preexistente. Para mitigar la fricción operativa inherente a la búsqueda de material de ‘stock’, la plataforma integra un motor de síntesis de imágenes estáticas basado en los modelos difusivos de Nanobanana 2. Este subsistema faculta a los creadores para materializar conceptos abstractos de forma instantánea mediante directivas textuales (prompts) directamente sobre el lienzo de edición. La ventaja técnica más significativa es la consciencia contextual multimodal de la red neuronal: la IA evalúa tanto el guion generado por Gemini como la paleta de colores de las escenas adyacentes para asegurar que la imagen sintetizada exhiba una coherencia estética absoluta con el resto del proyecto, erradicando la discrepancia visual y acelerando los ciclos de preproducción.
Generación visual y metraje fotorealista desde cero
La actualización más disruptiva en la capacidad de síntesis gráfica es la integración del modelo Veo 3.1. Históricamente, la creación de recursos visuales dependía de la ingesta manual de activos desde bancos de imágenes genéricos. Ahora, el ecosistema permite la síntesis de vídeo fluido a partir de imágenes estáticas, condicionando el espacio latente del modelo mediante directivas visuales y descripciones textuales. Esto garantiza que la red neuronal respete la paleta de colores corporativa o los elementos arquitectónicos específicos proporcionados en la imagen base. Un detalle operativo y estratégico crucial para los creadores actuales es que la generación de vídeo a partir de imagen en la plataforma no consume créditos en este momento, lo que habilita una experimentación masiva para perfeccionar las animaciones sin impactar los presupuestos del departamento.
Subtítulos dinámicos y accesibilidad corporativa
La retención de la audiencia en entornos digitales depende sustancialmente de la accesibilidad tipográfica. Observando las mecánicas de retención popularizadas por aplicaciones de edición rápida, Google Vids ha implementado un motor de subtitulación automática por inteligencia artificial que recuerda directamente a la fluidez de plataformas como CapCut. El sistema transcribe el audio con una precisión sobresaliente y sincroniza el texto en pantalla de forma rítmica para acompañar la locución. Aunque el nivel de personalización tipográfica y el abanico de animaciones de entrada es algo más conservador y restringido que en las herramientas enfocadas puramente a redes sociales, esta limitación estructural es intencional para garantizar la sobriedad, la uniformidad y la máxima legibilidad requeridas en comunicaciones institucionales serias.
Síntesis de avatares corporativos y el imperativo multilingüe
La solución logística a la fricción de la captura de talento humano en vídeo es el motor de avatares de IA de Google Vids. Esta funcionalidad permite instanciar presentadores digitales fotorrealistas o ilustrados que interpretan un guion directamente sobre la escena. El flujo de trabajo implica seleccionar el avatar desde un panel lateral, escribir el guion técnico —o delegar su generación a Gemini— y asignar una voz que corresponda al tono corporativo deseado. La innovación crítica introducida en la actualización de infraestructura de febrero de 2026, y el punto focal de la competitividad de Vids, es su capacidad de competencia multilingüe nativa con sincronización labial de alta fidelidad (Lip-Sync).
La red neuronal no solo clona la voz original del presentador seleccionado, sino que es capaz de sintetizar fluidamente discursos completos en decenas de idiomas extranjeros, manteniendo el mismo timbre y prosodia, eliminando la necesidad de doblajes costosos o localizaciones manuales. Sin embargo, la implementación de estos ‘actores sintéticos’ conlleva una penalización operativa. El renderizado de escenas con avatares de IA activos impone una intensidad computacional significativamente superior a la del contenido gráfico estándar o generado por Veo 3.1, lo que se traduce en cuotas estrictas de generación basadas en créditos corporativos y un aumento notable en el tiempo de procesamiento antes del despliegue final.
Identidad sintética y el control avanzado de voces expresivas
El enorme obstáculo logístico de grabar a un portavoz humano en un estudio ha sido neutralizado con la nueva generación de avatares sintéticos. La plataforma permite instanciar presentadores digitales que articulan el guion con sincronización labial de alta fidelidad. Los operadores pueden crear avatares personalizados o elegir perfiles predefinidos y modificarlos añadiendo ingredientes específicos para integrarlos orgánicamente en la narrativa de la marca. Para complementar esta presencia visual, el motor acústico ofrece perfiles de locución categóricos, como el perfil persuasor para embudos de ventas, el perfil educador para el sector académico o el perfil entrenador para discursos de liderazgo.
Para dominar estas nuevas voces profundamente expresivas y evitar resultados artificiales, el creador debe aplicar técnicas precisas en la redacción del texto. La regla fundamental es estructurar el guion para que no se solapen emociones contradictorias en una misma frase, forzando a la inteligencia artificial a realizar pausas lógicas. El control absoluto del tono, la emoción y la localización geográfica se logra inyectando comandos específicos entre corchetes directamente en el editor de texto. Por ejemplo, al iniciar un diálogo con la directiva [Español de España] o [Español de México], el motor asume instantáneamente esa cadencia fonética. Del mismo modo, se pueden forzar comportamientos acústicos utilizando expresiones como [Riendo], [Tono persuasivo], [Voz triste] o indicaciones de ritmo como [Pausa de 2 segundos] para modular la naturalidad de la entrega. Los operadores y diseñadores de producto pueden evaluar y calibrar la fidelidad de estas voces expresivas antes de su implementación accediendo a la consola de prueba en la documentación de Google Cloud o experimentando con los motores acústicos directamente en Google AI Studio.
Generación de música con Lyria 3 y Lyria 3 Pro
La inmersión audiovisual exige una infraestructura sonora que no dependa de licencias de terceros, un cuello de botella histórico en la producción corporativa. Para erradicar esta fricción operativa, Google Vids integra nativamente la familia de modelos de generación de audio de Google DeepMind. El núcleo de esta arquitectura es Lyria 3, un modelo especializado en sintetizar ráfagas acústicas de treinta segundos, diseñadas matemáticamente para transiciones o aperturas dinámicas. Cuando el proyecto exige una cama sonora prolongada, el sistema invoca a Lyria 3 Pro, capaz de mantener una estricta coherencia armónica en composiciones instrumentales continuas de hasta tres minutos. El operador parametriza la generación basándose en instrumentación, tempo y textura, mientras que el ecosistema aplica de forma imperativa un algoritmo de atenuación (audio ducking). Este subsistema deprime el volumen de las pistas generadas por Lyria en los milisegundos exactos en los que detecta frecuencias vocales provenientes del motor Gemini TTS o de los avatares sintéticos, garantizando una inteligibilidad narrativa prístina sin requerir un complejo enrutamiento manual de audio.
Nuestra experiencia real con las cuotas y la versión gratuita
Tras probar la herramienta a fondo, la estructura de cuotas de Google Vids resulta ser una gran ventaja competitiva, especialmente en su nivel de acceso básico. En las cuentas gratuitas, la plataforma permite generar vídeo sin consumir los créditos de Google Flow, lo que elimina de un plumazo una barrera económica clave para los creadores. Además, esta versión sin coste no se queda corta en funcionalidades: incluye el acceso a las voces expresivas del modelo Gemini TTS 3.0 y permite la creación automática de subtítulos generados por inteligencia artificial. Al dar el salto a la versión Pro, la generación de vídeo sigue sin consumir créditos, pero se desbloquean las herramientas de mayor carga computacional. Específicamente, los usuarios Pro ganan la capacidad de crear avatares digitales y acceder a la síntesis musical generativa, lo que permite componer pistas de treinta segundos con el modelo Lyria 3 o extenderse hasta piezas de tres minutos utilizando Lyria 3 Pro.
Impacto operativo y el riesgo de la homogeneización visual
La integración de este profundo arsenal generativo en Google Vids representa un avance sin precedentes para la eficiencia documental. Sin embargo, la dependencia exclusiva de estas automatizaciones conlleva un riesgo de homogeneización corporativa aguda. Si todas las organizaciones emplean las mismas plantillas, los mismos avatares predeterminados y las mismas estructuras de storyboard, el contenido perderá su impacto. El verdadero valor añadido para los profesionales residirá en su pericia para dominar los comandos vocales avanzados, personalizar el estilo mediante los ingredientes de los avatares y comprender que la máxima eficiencia técnica siempre debe ir de la mano de una dirección de arte humana.