Kimi k2.5, la Inteligencia Agéntica Visual que Jubila al Modelo Secuencial
Resumen Estructurado: La Revolución Kimi k2.5
El contexto: Moonshot AI lanza Kimi k2.5, un modelo nativamente multimodal (15T tokens) que rompe el paradigma del «agente único» mediante enjambres colaborativos y visión profunda.
El modelo no solo describe imágenes; entiende flujos de vídeo. Puedes grabar una interacción web y Kimi generará el código (React/Vue) replicando la lógica y el diseño, eliminando la fricción entre diseño y desarrollo.
Adiós al cuello de botella secuencial. Kimi k2.5 puede instanciar hasta 100 sub-agentes en paralelo para tareas complejas, reduciendo el tiempo de resolución en un 450% y evitando el colapso por error único.
- Rendimiento: Supera a Claude 4.5 Opus en navegación y empata con Gemini 3 Pro en vídeo.
- Coste: Open Weights (gratis si tienes hardware) o API ultra-low-cost ($0.60/1M tokens).
- Matemáticas: Sigue ligeramente por debajo de GPT-5.2 (96% vs 100%), pero la diferencia es marginal para la mayoría de usos.
Ya no se trata de tener el modelo más listo, sino de cuántos modelos puedes poner a trabajar a la vez. El «Single-Agent» ha muerto.
«En 2026, la barrera de entrada no es el conocimiento, es la capacidad de orquestar agentes.»
Si pensábamos que la batalla de 2026 estaba en el tamaño de la ventana de contexto, Moonshot AI acaba de cambiar las reglas del juego. Con el lanzamiento de Kimi k2.5, no solo presentan un modelo «nativamente multimodal» entrenado con 15 billones (trillions) de tokens mixtos; presentan una arquitectura que hace que el concepto de «un prompt, una respuesta» parezca tecnología de la edad de piedra.
Lo que revela su Technical Report es inquietante y fascinante a la vez: ya no estamos ante un asistente que charla, sino ante un enjambre autónomo capaz de ver, codificar y auto-gestionarse en paralelo.
Score: 43.2
Score: 78.4
Score: 77.1
Verified
Score: 76.8 (Open SOTA)
Multi
Score: 73.0
Score: 81.0
Score: 84.2
Score: 88.8
Score: 86.6
Score: 79.8
1. «Coding with Vision»: Del Pixel a la Estructura Lógica
La capacidad más disruptiva confirmada en el reporte es la programación visual nativa. Kimi k2.5 no «interpreta» imágenes de forma pasiva; razona sobre flujos de vídeo para generar código funcional.
Esta capacidad, denominada «Coding with Vision», rompe la barrera tradicional de describir interfaces con texto. En sus demostraciones técnicas, el modelo es capaz de observar un vídeo de una web en funcionamiento y reconstruir su frontend completo, infiriendo no solo la estética, sino las interacciones dinámicas (como efectos de scroll o animaciones).
El Caso «Matisse»: Autocorrección Visual
El ejemplo más potente del reporte muestra al modelo utilizando la estética de La Danza de Matisse para diseñar una web. Lo revolucionario no es el diseño, sino el proceso: Kimi k2.5 inspeccionó visualmente su propio resultado, detectó discrepancias con la referencia artística y se depuró a sí mismo de forma autónoma, iterando sobre el código hasta lograr la fidelidad visual deseada sin intervención humana.
2. Agent Swarm & PARL: La Fuerza del Enjambre
Aquí es donde la arquitectura se separa radicalmente de lo visto en OpenAI o Anthropic. Kimi k2.5 introduce los «Agent Swarms» (Enjambres de Agentes) auto-dirigidos, entrenados bajo un nuevo paradigma llamado PARL (Parallel-Agent Reinforcement Learning).
Tradicionalmente, los agentes fallan por «colapso serial»: intentan hacer todo paso a paso y, si uno falla, la cadena se rompe. Kimi k2.5 elimina este cuello de botella:
- Orquestación Masiva: El modelo instancia automáticamente hasta 100 sub-agentes especializados que trabajan en paralelo sobre una misma tarea compleja.
- Reducción de Latencia: Al ejecutar flujos de trabajo concurrentes (soportando hasta 1.500 llamadas a herramientas), reduce el tiempo de ejecución en un 450% (4.5x) comparado con configuraciones de agente único.
- Entrenamiento PARL: Este sistema de aprendizaje por refuerzo penaliza la ejecución secuencial innecesaria y premia la paralelización temprana, obligando al modelo a pensar como un jefe de proyecto que delega, no como un operario que ejecuta.
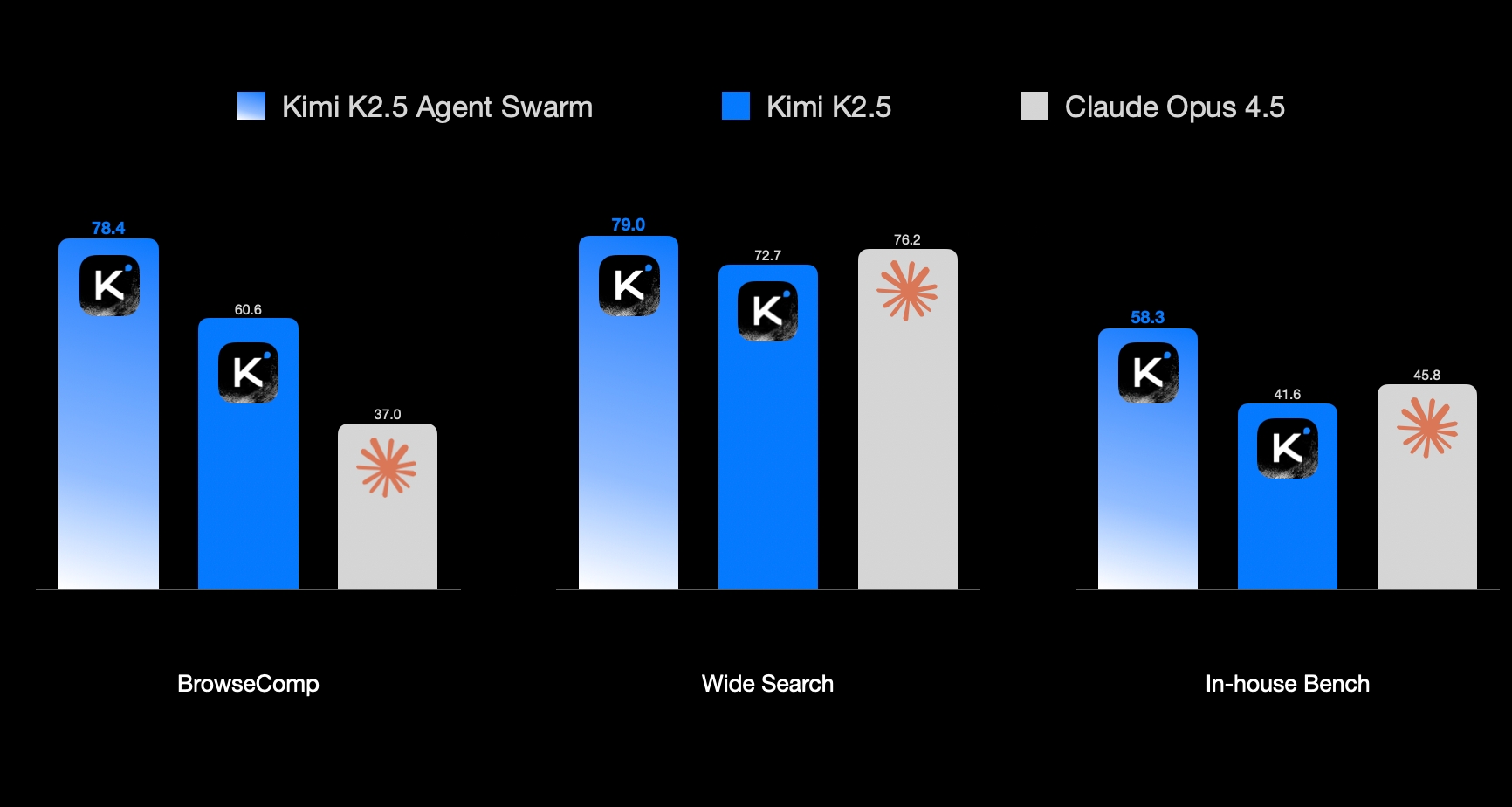
3. Benchmarks: Mirando a los Ojos a GPT-5.2 y Gemini 3
El apéndice del reporte pone nombres y apellidos a la competencia de 2026. Los números de Kimi k2.5 (en su versión Thinking) demuestran que el Open Source ya no es la «alternativa barata», sino un competidor directo en la gama alta.
| Benchmark | Kimi K2.5 (Thinking) |
GPT-5.2 (xhigh) |
Claude 4.5 (Opus) |
Gemini 3 Pro (Thinking) |
|---|---|---|---|---|
| Reasoning & Knowledge | ||||
| AIME 2025 (Math) | 96.1 | 100.0 | 92.8 | 95.0 |
| GPQA-Diamond | 87.6 | 92.4 | 87.0 | 91.9 |
| Image & Video | ||||
| VideoMMMU | 86.6 | 85.9 | 84.4 | 87.6 |
| MathVista (Visual) | 90.1 | 82.8 | 80.2 | 89.8 |
| Coding & Agents | ||||
| SWE-Bench Verified | 76.8 | 80.0 | 80.9 | 76.2 |
| BrowseComp (Agents) | 78.4 | — | — | — |
Análisis de los datos:
- Matemáticas: Con un 96.1% en AIME 2025, supera a Gemini 3 Pro y se queda a las puertas de la perfección teórica de GPT-5.2.
- Video: En VideoMMMU, supera a Claude 4.5 Opus y GPT-5.2, validando su entrenamiento nativo con vídeo frente a modelos que solo procesan frames estáticos.
- Código: Aunque Claude 4.5 Opus mantiene una ligera ventaja en SWE-Bench Verified (80.9% vs 76.8%), Kimi k2.5 supera a Gemini 3 Pro y se posiciona como la opción abierta más robusta para ingeniería de software.
4. Productividad de «Oficina»: El Analista Incansable
Más allá del código, Moonshot AI ha optimizado el modelo para la burocracia corporativa pesada, un área a menudo ignorada por los modelos de «razonamiento puro».
El reporte detalla su capacidad para manejar documentos masivos de hasta 100 páginas o 10.000 palabras de una sola vez. En el benchmark interno AI Office, ha demostrado una mejora del 59.3% respecto a su predecesor (K2). No solo resume; puede generar diapositivas, crear hojas de cálculo con tablas dinámicas complejas y redactar documentos legales con formato LaTeX directamente desde una conversación, reduciendo tareas de horas a minutos.
5. La Letra Pequeña: El Espejismo de la Gratuidad
Es crucial despejar la confusión habitual entre «Open Source» y «Gratis», pues aunque Kimi k2.5 libera sus pesos, el coste real se esconde en el hardware o en las restricciones de uso. Quien decida descargar el modelo para ejecutarlo en local se encontrará con una barrera física insalvable para la mayoría: mover un modelo de más de un billón de parámetros requiere aproximadamente 240 GB de memoria unificada, lo que restringe su uso «gratuito» a poseedores de clústeres de H100 o estaciones de trabajo de gama ultra alta tipo Mac Studio Ultra. Para el usuario doméstico, la soberanía de los datos tiene un precio de hardware prohibitivo.
Por otro lado, la versión web accesible a través de Kimi.ai ofrece una capa gratuita que funciona más como una demostración técnica que como una herramienta de producción ilimitada. Moonshot aplica límites dinámicos de uso (rate-limits) que se vuelven especialmente agresivos cuando se activa el «Thinking Mode» o se suben vídeos largos. Aunque sobre el papel la ventana de contexto alcanza cifras masivas, en la interfaz web gratuita el usuario experimentará cuellos de botella y degradación de rendimiento si intenta abusar del sistema continuadamente. Para uso profesional real, la vía sostenible es la API, que si bien es de pago, rompe el mercado con precios hasta seis veces inferiores a GPT-5.2, costando apenas 0,60 dólares por millón de tokens de entrada.
Conclusión: ¿Ha Muerto la Suscripción de 20 Dólares?
La llegada de Kimi k2.5 obliga a replantear si tiene sentido seguir pagando las mensualidades de ChatGPT Plus o Claude Pro. La respuesta técnica es que, en términos de fuerza bruta matemática y codificación pura, GPT-5.2 y los modelos o3 siguen manteniendo una ligera ventaja en los percentiles más altos de dificultad. Si tu trabajo depende de la precisión absoluta en física teórica o matemáticas de competición, los modelos de pago occidentales retienen todavía la corona por un margen estrecho.
Sin embargo, Kimi k2.5 gana la batalla en el terreno de la utilidad real y la relación calidad-precio. Su capacidad nativa para entender vídeo y, sobre todo, su arquitectura de enjambre para la navegación web autónoma, superan hoy a lo que ofrecen Claude 4.5 Opus o Gemini 3 Pro. Estamos ante un punto de inflexión donde un modelo abierto y accesible ofrece el 95% del rendimiento de la vanguardia a una fracción del coste o incluso gratis si se aceptan las limitaciones de la web. Para el desarrollador, el creador de contenido o el analista medio, la «tasa OpenAI» ha dejado de ser un peaje obligatorio para convertirse en un lujo opcional.