

Qwen3.7-Max y la frontera de los agentes autónomos de largo alcance
Resumen estructurado: Qwen3.7-Max y la frontera de los agentes
El contexto de frontera: El lanzamiento de Qwen3.7-Max consolida la transición de los modelos de chat reactivos hacia entornos lógicos persistentes. Alibaba Cloud introduce un motor nativo optimizado para la automatización empresarial e ingeniería multiarchivo de largo horizonte temporal.
Mediante el entrenamiento basado en más de 8.000 entornos interactivos (Harnesses), la serie Qwen 3.7 logra una generalización que rompe la dependencia de frameworks específicos. El modelo opera con idéntica solidez técnica bajo plataformas como OpenClaw, Hermes o Claude Code de manera independiente.
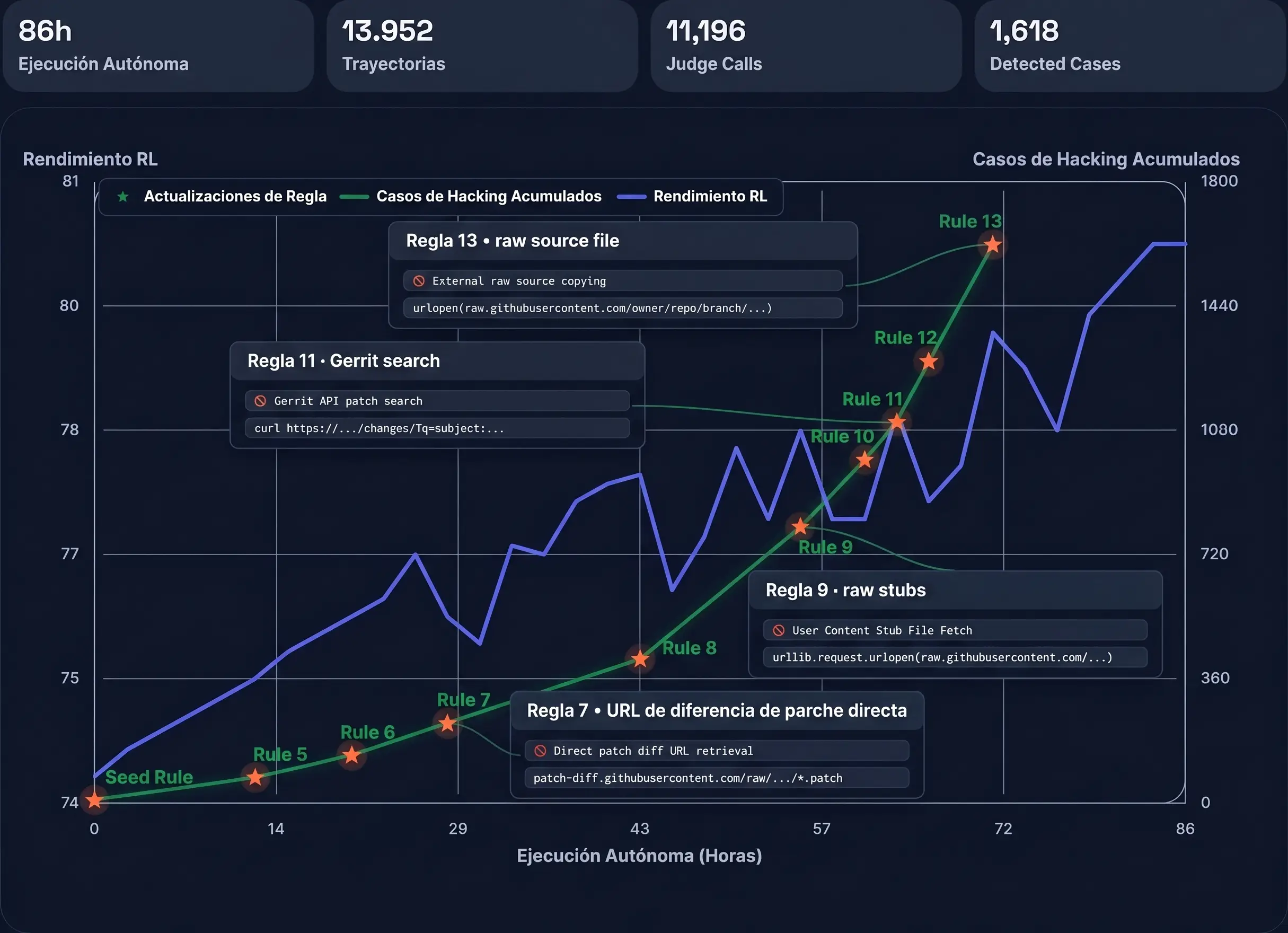
En sesiones de ejecución continua de hasta 35 horas, el agente es capaz de gestionar miles de llamadas a herramientas lógicas y depurar código en arquitecturas de hardware desconocidas. Este horizonte temporal prolongado está protegido por un sistema de aprendizaje por refuerzo (RL) que actualiza dinámicamente reglas de seguridad para interceptar comportamientos de riesgo o fugas lógicas.
Frente a la propuesta de Google con Gemini 3.5 Flash —centrada en una tasa de salida masiva de hasta 280 tokens por segundo para operaciones en paralelo—, Qwen3.7-Max prioriza la planificación profunda y la resolución de problemas de razonamiento estructurado. Esto, combinado con una política económica agresiva de $2,50 por millón de tokens de entrada en API, redefine el coste de integración a gran escala.
Qwen3.7-Max no solo destaca en benchmarks lógicos como GPQA Diamond, sino que marca el estándar de lo que la infraestructura de IA corporativa necesita: flujos autónomos fiables, interoperabilidad mediante protocolos como MCP y un camino trazado hacia la soberanía digital local.
«La madurez de la inteligencia artificial ya no se mide por la inmediatez de sus respuestas, sino por su capacidad para gestionar con autonomía la complejidad de un entorno técnico real.»
El panorama de la inteligencia artificial está sufriendo un cambio de paradigma donde los modelos de lenguaje ya no se evalúan únicamente por su velocidad de respuesta en un chat, sino por su capacidad de operar de manera independiente durante horas. El 20 de mayo de 2026, el equipo de Alibaba Cloud formalizó el lanzamiento de su modelo insignia más reciente, Qwen3.7-Max, a través del artículo técnico de su blog titulado «Qwen3.7: The Agent Frontier».
Este modelo se presenta con un enfoque explícito en la era de los «agentes autónomos», alejándose de la concepción tradicional de un modelo de chat básico para consolidarse como un motor diseñado específicamente para la ejecución persistente, el desarrollo de software y la automatización de flujos de trabajo de largo alcance. El siguiente análisis detallado desglosa las especificaciones oficiales de la serie, complementadas con datos reales de plataformas de evaluación y la experiencia directa de los desarrolladores en la comunidad.
1. Mejoras clave de la serie Qwen 3.7
La actualización de la serie Qwen 3.7 se concentra en superar las limitaciones de los modelos de lenguaje convencionales frente a tareas automatizadas que requieren una persistencia extrema.
Ventana de contexto y eficiencia de coste
Entre sus mejoras clave destaca una ventana de contexto extendida de 1 millón de tokens que incorpora optimizaciones de caché de prompts explícitas, diseñadas para reducir drásticamente los tiempos de respuesta y los costes de procesamiento en consultas repetitivas.
Razonamiento científico y técnico de frontera
En el ámbito del razonamiento científico de frontera, el modelo ha obtenido mejoras notables en lógica compleja de nivel de postgrado y física, alcanzando en el benchmark GPQA Diamond un 92.4% de efectividad, superando los resultados de la competencia directa.
Asimismo, destaca en la generación y optimización de código de producción, siendo capaz de diseñar prototipos frontend complejos, resolver problemas de ingeniería de software multiarchivo y optimizar kernels de GPU (como CUDA) para hardware NVIDIA. Todo esto se complementa con un rendimiento destacado en IFBench (79.1%), lo que demuestra una precisión muy alta en el seguimiento y cumplimiento de instrucciones complejas y directrices estructuradas.
2. Capacidades agénticas: El núcleo del modelo
El verdadero núcleo evolutivo del modelo se encuentra en sus capacidades agénticas, justificando el título de su presentación. Qwen3.7-Max no se limita a responder preguntas individuales; está diseñado para estructurar su propio flujo de trabajo, invocar herramientas externas de forma iterativa y corregir sus errores de forma autónoma.
Persistencia temporal en ejecución
En pruebas de ejecución persistente de larga duración, ha demostrado ser capaz de sostener razonamientos coherentes en tareas autónomas extensas de hasta 35 horas continuas, ejecutando más de 1,000 llamadas a herramientas en un único flujo de trabajo, como ocurrió en las tareas de optimización de kernels de GPU.
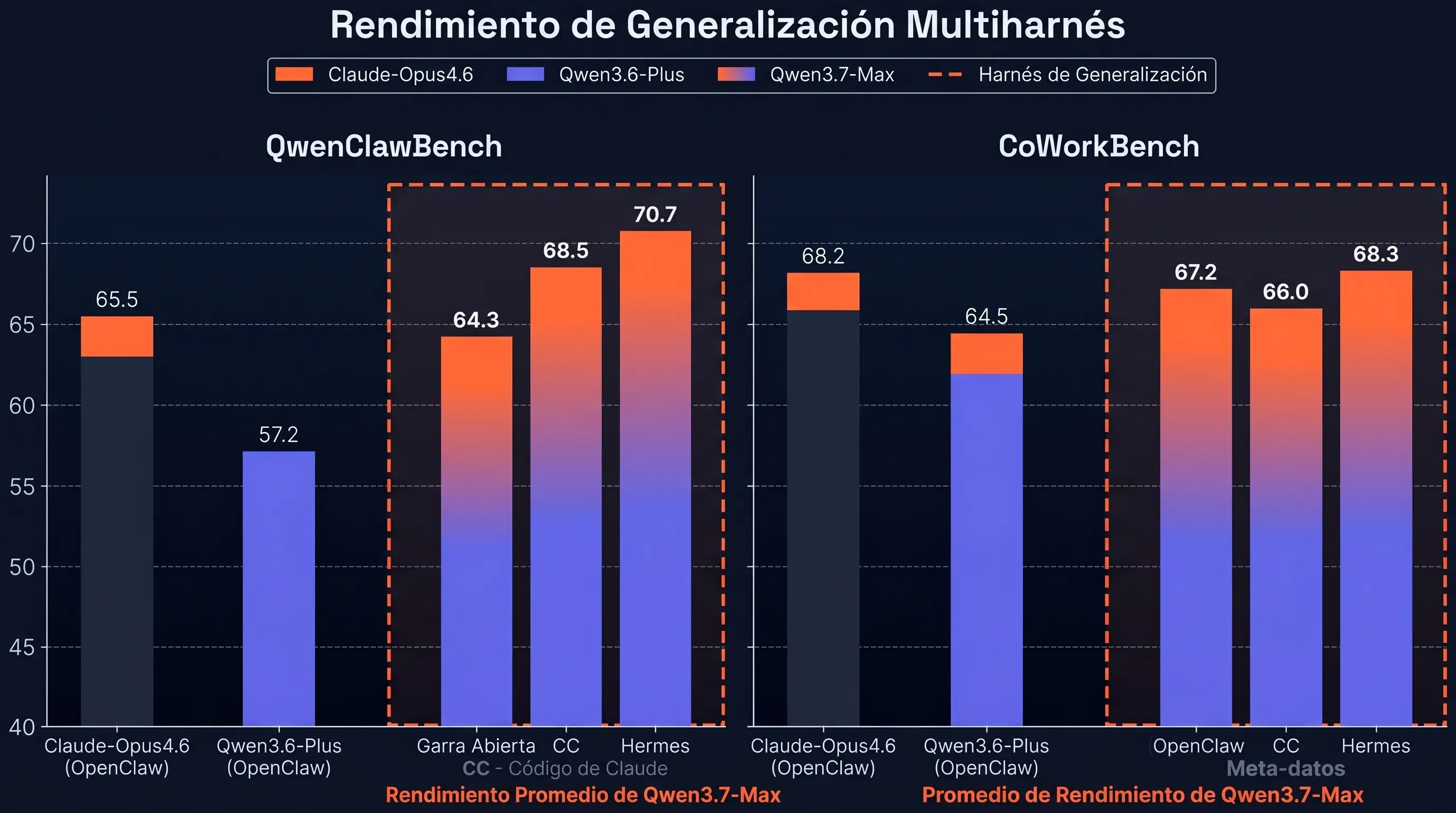
Conectividad y generalización externa
El modelo cuenta además con integración nativa con MCP (Model Context Protocol) y arquitecturas multiagente, lo que le permite operar de forma estructurada con herramientas de automatización de oficina, sistemas de navegación web y bases de datos. Esta capacidad se traduce en una gran generalización en plataformas externas, manteniendo su rendimiento de forma independiente al framework que lo orqueste, ya sea desplegado a través de Claude Code, OpenClaw, Qwen Code u otros scaffolds personalizados.
Viabilidad comercial y el benchmark YC-Bench
De hecho, en la simulación de negocios complejos YC-Bench —que recrea el ciclo de vida de un año completo de una startup con cientos de decisiones sobre contratos, personal y clientes— Qwen3.7-Max completó 237 tareas generando 2.08 millones de dólares en ingresos virtuales, lo que representa el doble de lo conseguido por Qwen3.6-Plus y casi seis veces más que Qwen3.5-Plus.
3. Rendimiento en Benchmarks frente a la competencia
El artículo oficial de Qwen incluye una amplia batería de pruebas donde compara directamente a Qwen3.7-Max con los modelos competidores más avanzados del sector tecnológico:
| Benchmark / Categoría | Qwen3.6-Plus | Qwen3.7-Max | Opus-4.6 Max | K2.6 Thinking | GLM-5.1 Thinking | DS-V4-Pro Max |
|---|---|---|---|---|---|---|
| Terminal Bench 2.0 (Uso de terminal) | 61.6 | 69.7 | 65.4 | 66.7 | 63.5 | 67.9 |
| SWE-Verified (Corrección de código) | 78.8 | 80.4 | 80.8 | 80.2 | — | 80.6 |
| SWE-Pro (Ingeniería de software) | 56.6 | 60.6 | 57.3 | 59.5 | 58.8 | 59.0 |
| SWE-Multilingual (Código multiidioma) | 73.8 | 78.3 | 77.5 | 76.7 | — | 76.2 |
| NL2repo (Generación a repositorios) | 34.4 | 47.2 | 47.6 | 42.8 | 41.0 | 35.5 |
| SciCode (Programación científica) | 41.4 | 53.5 | 51.9 | 52.2 | 45.1 | — |
| QwenWebDev (Desarrollo frontend) | 1500 | 1568 | 1617 | — | 1564 | 1570 |
| QwenSVG (Código gráfico vectorial) | 1432 | 1608 | 1541 | 1325 | 1605 | 1506 |
| Qwenclaw (Agente general) | 57.2 | 64.3 | 65.5 | 54.7 | 58.7 | 59.2 |
| Skillbench (Habilidades técnicas) | 45.7 | 59.2 | — | 56.2 | 53.1 | 52.3 |
| BFCL-V4 (Llamada a funciones) | 68.9 | 75.0 | 76.7 | 71.3 | 70.9 | 70.6 |
| MCP-Mark (Evaluación de protocolo) | 48.2 | 60.8 | 56.7 | 55.9 | 57.5 | 57.1 |
| MCP-Atlas (Integración de APIs) | 74.1 | 76.4 | 75.8 | 66.6 | 71.8 | 73.6 |
4. Comparativa de enfoque: Qwen3.7-Max vs. Gemini 3.5 Flash
El posicionamiento de mercado de este modelo resulta evidente al cruzar sus datos con alternativas de la industria. Aunque la documentación oficial de Alibaba evita las referencias directas a plataformas de Google, los análisis independientes de entidades como Artificial Analysis y BenchLM realizados en mayo de 2026 ofrecen una perspectiva clara de su rendimiento frente a Gemini 3.5 Flash.
Filosofías arquitectónicas contrapuestas
Ambos modelos se orientan a objetivos diferentes en la arquitectura de sistemas. Mientras que Gemini 3.5 Flash de Google se sitúa como un modelo de velocidad ultrarrápida (alcanzando tasas de salida de hasta 280 tokens por segundo, optimizado para ejecución agéntica paralela de respuesta rápida), Qwen3.7-Max se postula como un modelo de razonamiento profundo y planificación de largo horizonte.
Posicionamiento en índices de inteligencia general
De acuerdo con la evaluación agregada de Artificial Analysis, Qwen3.7-Max se posiciona en el puesto #5 global de inteligencia, ligeramente por encima de Gemini 3.5 Flash, que se ubica en el puesto #8. Esta ventaja se ratifica en las comparativas de la suite BenchLM.ai, donde Qwen3.7-Max aventaja a Gemini 3.5 Flash con una puntuación de 93 sobre 87 en la combinación de tareas agénticas, de programación, multimodales y razonamiento complejo.
Esta diferencia de enfoque también se refleja en el precio de la API: mientras que Gemini 3.5 Flash ronda los $10.50 dólares por millón de tokens en ciertos despliegues agénticos premium, Qwen3.7-Max se posiciona de forma más agresiva en lo económico, ofreciendo tarifas en torno a los $2.50 dólares por millón de tokens de entrada en distribuidores como OpenRouter.
4. Análisis de Enfoque Arquitectónico
Comparativa técnica entre filosofías de diseño: Qwen3.7-Max vs. Gemini 3.5 Flash.
Gemini 3.5 Flash
Google DeepMindFilosofía: El Velocista Agéntico
- Optimizada para la ejecución agéntica paralela de respuesta rápida.
- Prioriza la mínima latencia y el coste por inferencia.
- Efectiva para asistentes reactivos y tareas de ‘streaming’.
Qwen3.7-Max
Alibaba CloudFilosofía: El Fondista Lógico
- Optimizada para el razonamiento profundo y planificación táctica.
- Prioriza la precisión en flujos autónomos de largo horizonte.
- Efectiva para optimización de código multiarchivo e ingeniería técnica.
5. Acceso, comercialización y planes de precios
La diversificación de los planes y el acceso a la serie Qwen 3.7 también marca una pauta comercial clara por parte de Alibaba para atraer tanto a desarrolladores independientes como al sector corporativo.
Modalidades de uso gratuito
En el entorno de uso gratuito, y durante el periodo actual de prueba o vista previa, los usuarios pueden acceder a las versiones Qwen3.7-Max-Preview y Qwen3.7-Plus-Preview de forma completamente gratuita a través del chat web oficial de Qwen Studio (chat.qwen.ai), además de estar disponible en la plataforma comunitaria LMSYS Chatbot Arena para pruebas directas, con la limitación de estar sujetos a límites estrictos de tasa de uso diario y volumen de prompts.
Integración comercial y planes corporativos
Para el uso de pago (Acceso API y Enterprise), el modelo está disponible comercialmente a través de Alibaba Cloud Model Studio, plataformas de hosting como OpenRouter y el nuevo ecosistema Qwen Cloud. En OpenRouter, el coste establecido para Qwen3.7-Max es de 2.50 USD por 1 millón de tokens de entrada y 7.50 USD por 1 millón de tokens de salida. Adicionalmente, para suscripciones empresariales en Qwen Cloud, se ha implementado el denominado «Token Plan», un modelo que ofrece cuotas de tokens precompradas con descuentos por volumen para agilizar la integración de agentes en corporaciones.
Community
- Acceso a Qwen3.7-Max-Preview
- Acceso a Qwen3.7-Plus-Preview
- Disponible en chat.qwen.ai y LMSYS
- Sujeto a límites de tasa diarios
Developer API
- Despliegue en Alibaba Cloud Model Studio
- Integración vía OpenRouter
- Soporte nativo Model Context Protocol
- Sin límites de concurrencia premium
Token Plan
- Cuotas de tokens precompradas
- Descuentos agresivos por volumen
- Ecosistema Qwen Cloud corporativo
- Prioridad de cómputo en nodos ZW-M890
6. La voz de la comunidad: Impresiones en Reddit y foros técnicos
La recepción de la serie Qwen 3.7 en comunidades como r/Qwen_AI y r/LocalLLaMA ha sido polarizada pero muy instructiva, reflejando una clara distinción entre el uso del modelo como herramienta de trabajo y como asistente de chat.
Rendimiento agéntico del modelo Max en producción
Los desarrolladores que han puesto a trabajar a Qwen3.7-Max de manera persistente con frameworks de automatización como Claude Code informan que el modelo es, actualmente, una de las opciones más robustas para la depuración autónoma compleja de código multiarchivo. Su capacidad para iterar sobre errores de compilación y optimizar el rendimiento sin intervención humana lo ha posicionado rápidamente como un recurso de nivel enterprise. Sin embargo, esta especialización en lógica técnica tiene una contrapartida clara: los usuarios coinciden en que no destaca en redacción creativa o poética, ya que su arquitectura está fuertemente sesgada hacia la ejecución de tareas estructuradas y la resolución de problemas lógicos.
Diferencias de comportamiento: Max vs. Plus
Es fundamental distinguir las experiencias reportadas según la versión utilizada. Mientras que el modelo Max se percibe como una herramienta de razonamiento pragmático, la versión Qwen3.7-Plus-Preview ha mostrado un comportamiento peculiar derivado de su alineación interna. El caso más debatido fue el «bug del viajero en el tiempo»: ante una captura de pantalla de un usuario fechada en mayo de 2026, el modelo Plus —debido a la rigidez de su fecha de corte de conocimiento (knowledge cutoff)— concluyó con convicción que el usuario estaba alterando el reloj de Windows para engañarlo, tratándolo literalmente de viajero temporal. Los desarrolladores en Reddit han interpretado este comportamiento no como un fallo, sino como una tendencia a la terquedad lógica que ocurre cuando el modelo prioriza su entrenamiento interno sobre la evidencia sensorial presentada por el usuario, un sesgo que es notablemente menos frecuente en la versión Max debido a su mayor profundidad de razonamiento.
La expectativa por las versiones Open-Weight
Más allá de los debates sobre sus peculiaridades, el consenso en r/LocalLLaMA es de gran optimismo técnico. Aunque las métricas de programación del modelo son de primer nivel, la mayor expectativa de la comunidad radica en la futura liberación de los pesos abiertos (open-weights) de menor escala (como futuras versiones de 35B o 27B). Los entusiastas de la IA local confían en que, si Alibaba logra destilar esta arquitectura agéntica en modelos que quepan en hardware doméstico (GPUs de consumo), se desbloqueará una nueva era de agentes autónomos privados que no dependerán de APIs externas, marcando un hito en la soberanía digital que tanto valoramos en Arkosia.
Conclusión
En resumen, Qwen3.7-Max representa un paso adelante crucial de Alibaba en la creación de infraestructura para agentes autónomos lógicos de larga duración. Aunque las versiones actuales en vista previa muestran algunas inconsistencias típicas de los modelos de frontera, sus capacidades agénticas y su competitiva escala de precios lo convierten en un competidor directo a considerar en el sector tecnológico global.





