

Gemma 4 trae el razonamiento profundo a los modelos de IA locales
Resumen estructurado sobre la arquitectura de Gemma 4
El contexto: Google DeepMind redefine los modelos de pesos abiertos (licencia Apache 2.0). Gemma 4 abandona la simple generación de texto para integrar razonamiento profundo y multimodalidad nativa, acercando capacidades propietarias al hardware de consumo.
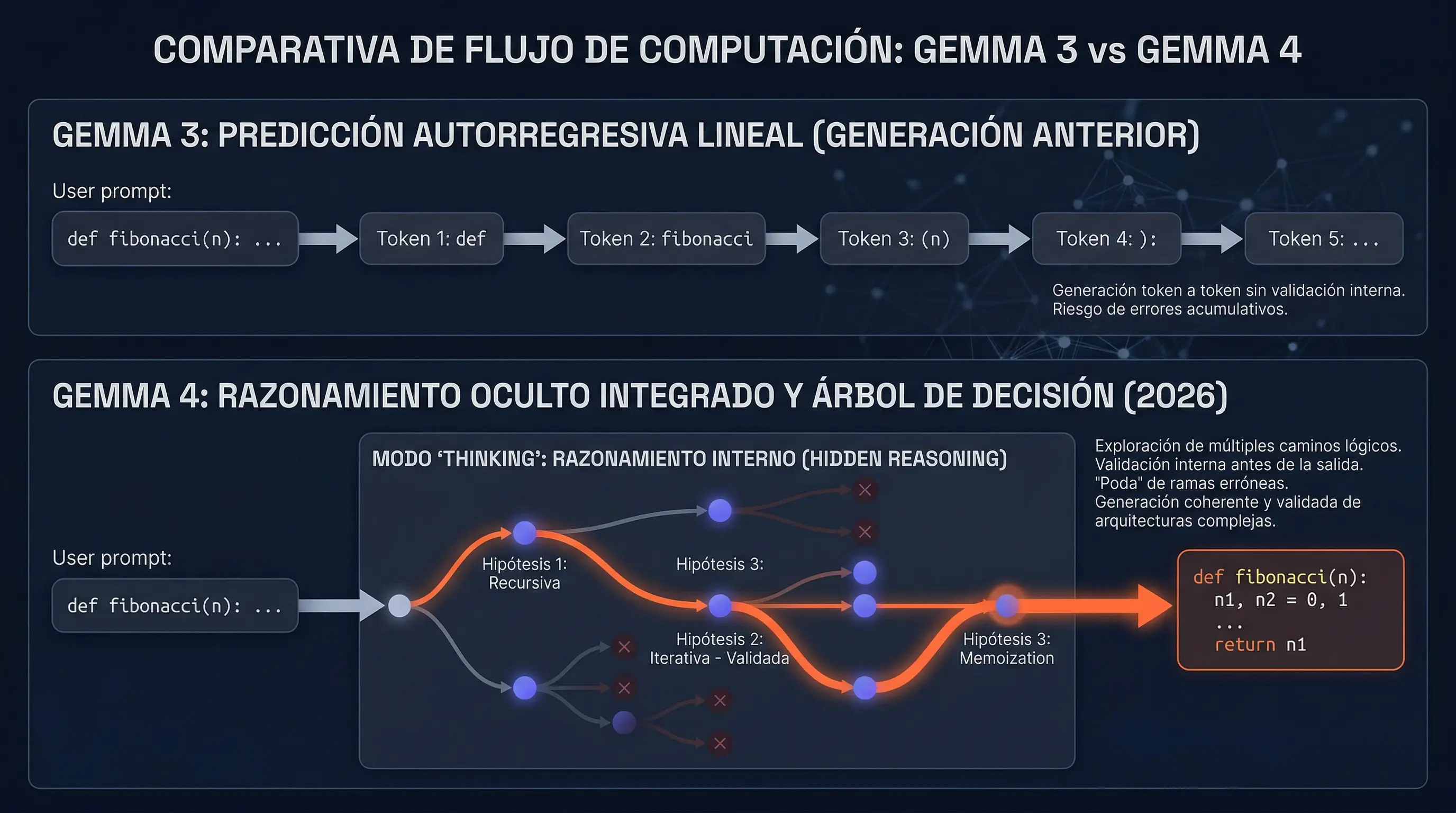
El modelo abandona la predicción lineal autorregresiva. Ahora crea un árbol de decisión interno, deteniéndose a evaluar y desglosar lógicamente los problemas paso a paso antes de emitir la respuesta final, reduciendo drásticamente las alucinaciones en código.
Google despliega cuatro modelos: E2B y E4B para el borde, junto a los pesados 26B (Mixture of Experts) y 31B (Dense) para servidores. Estos últimos alcanzan ventanas de contexto de hasta 256K tokens, permitiendo la ingesta de repositorios completos.
La optimización técnica permite ejecutar inteligencia artificial avanzada directamente en dispositivos móviles mediante la aplicación Edge Gallery con las siguientes especificaciones:
- Eficiencia de memoria: Ejecución del modelo E2B con menos de 1.5GB de RAM gracias a cuantización a 2 y 4 bits.
- Hardware soportado: Rendimiento superior a 130 tokens/segundo en placas como la Raspberry Pi 5.
- Agentes locales: Capacidad para ejecutar herramientas, consultar el SO y procesar audio/visión de forma 100% offline.
Democratiza la computación agéntica de vanguardia, exigiendo a su vez una evolución acelerada en el perfil del desarrollador moderno.
«Gemma 4 certifica la transición del desarrollador humano: de picador de código manual a orquestador de sistemas autónomos.»
El ecosistema de inteligencia artificial abierta ha encontrado un nuevo punto de inflexión estructural. Google DeepMind ha presentado la familia Gemma 4, una actualización masiva que replantea desde los cimientos lo que los desarrolladores y creadores pueden lograr utilizando modelos de pesos abiertos bajo la permisiva licencia Apache 2.0. Lejos de representar una simple mejora incremental en la calidad del texto, esta cuarta generación introduce capacidades de razonamiento profundo, ventanas de contexto colosales y una multimodalidad nativa que hasta hace poco eran territorio exclusivo de las APIs propietarias más costosas.
La revolución del razonamiento integrado paso a paso
La mejora más radical que presenta Gemma 4 es la incorporación de un modo de procesamiento interno que simula el razonamiento humano. En generaciones anteriores, los modelos operaban principalmente mediante la predicción probabilística del siguiente token, lo que a menudo derivaba en errores lógicos al enfrentar tareas complejas. Ahora, la arquitectura heredada de Gemini 3 permite a Gemma 4 detenerse a pensar y desglosar internamente los problemas paso a paso antes de emitir una sola palabra de respuesta. Este proceso de computación oculta resulta invaluable en escenarios de alta exigencia, como la generación de arquitecturas de software enteras, la estructuración de temarios educativos dinámicos o la resolución de problemas de lógica matemática avanzada donde un solo error en la cadena anula el resultado final.
Gestión de contexto masivo para análisis documental
Las limitaciones a la hora de procesar grandes volúmenes de información han quedado obsoletas gracias a la nueva gestión de memoria del modelo. Las variantes de mayor tamaño han expandido su capacidad para alcanzar los 256K tokens de ventana de contexto, mientras que los modelos más ligeros orientados a dispositivos de borde garantizan hasta 128K tokens. En la práctica del desarrollo diario, esta expansión significa que un programador puede introducir en un único prompt libros técnicos enteros, manuales de normativas extensas o repositorios completos de código fuente. La gran ventaja técnica es que el modelo es capaz de extraer relaciones cruzadas entre el inicio y el final de estos documentos masivos sin perder el hilo conductor ni sufrir degradación en su capacidad de recuperación de datos.
Multimodalidad nativa y optimización para hardware de consumo
El despliegue de inteligencia artificial local adquiere una nueva dimensión con los modelos E2B y E4B. La documentación oficial de la tarjeta de modelo confirma que estas arquitecturas han sido diseñadas para operar con una eficiencia extrema. Las pruebas de estrés realizadas por la comunidad especializada en ejecución local demuestran que, aplicando formatos de cuantización modernos, la versión base puede ejecutarse de forma fluida con un requerimiento mínimo de apenas 5GB de memoria RAM unificada.
Esta optimización extrema permite que un ordenador portátil estándar del año actual ejecute tareas de visión por computadora y procesamiento de audio directo en tiempo real. Esto facilita a los desarrolladores implementar funciones de reconocimiento y traducción de voz totalmente offline, reduciendo la latencia de respuesta a escasos milisegundos y garantizando una privacidad absoluta de los datos del usuario.
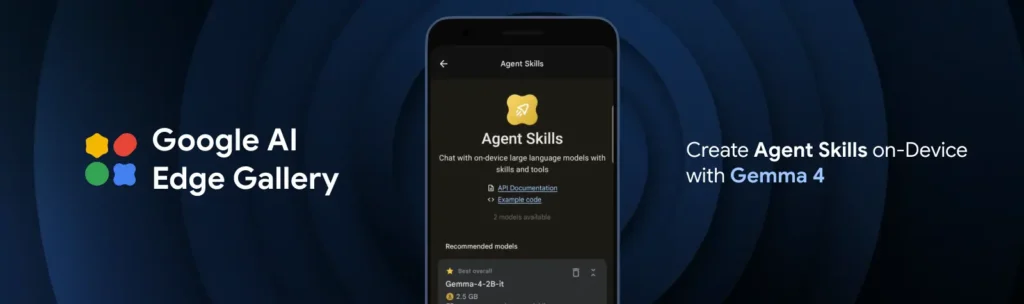
Habilidades agénticas y experimentación local en Android
La integración de capacidades autónomas en dispositivos móviles y de hardware limitado representa uno de los pilares fundamentales de esta actualización. A través de la aplicación Google AI Edge Gallery, los desarrolladores disponen de un entorno oficial para testear el rendimiento de los modelos E2B y E4B. Esta plataforma estrena la función de habilidades agénticas, permitiendo ejecutar flujos de trabajo autónomos de múltiples pasos totalmente en el dispositivo. En la práctica, esto otorga al modelo la capacidad de consultar fuentes externas de forma local para aumentar su base de conocimiento, generar gráficos interactivos analizando datos del usuario o integrarse con otros modelos residentes para sintetizar música a partir de fotografías, todo ello de forma conversacional.
El verdadero motor de software detrás de esta revolución en el borde es la implementación de LiteRT-LM, la biblioteca de ejecución que permite exprimir al máximo las capacidades del hardware. Gracias al soporte avanzado para la cuantización de pesos a dos y cuatro bits, es posible ejecutar el modelo E2B consumiendo menos de un gigabyte y medio de memoria RAM. Esta optimización técnica incluye mecanismos de decodificación restringida, lo que garantiza que las llamadas a herramientas y las respuestas de los agentes sigan estructuras predecibles en entornos de producción. El rendimiento documentado en placas de bajo coste como la Raspberry Pi 5 alcanza cifras sorprendentes, superando los ciento treinta tokens por segundo en la fase de asimilación del contexto, lo que viabiliza la creación de controladores domóticos, robótica y asistentes de voz que operan bajo estricto aislamiento de la red.
Segmentación técnica de los cuatro modelos disponibles
Para asegurar que la tecnología sea aplicable a cualquier entorno de desarrollo, Google ha segmentado esta familia en cuatro variantes específicas. En el extremo de la eficiencia encontramos los modelos optimizados para teléfonos móviles, placas como Raspberry Pi y hardware limitado. Es en este ecosistema donde destaca la aplicación Google AI Edge Gallery para Android, un entorno que permite a los usuarios experimentar localmente con el rendimiento multimodal y testear funciones de agentes autónomos que interactúan directamente con el sistema operativo del teléfono.
En el otro extremo del espectro de rendimiento se sitúan los pesos pesados para servidores locales y centros de datos. El modelo 26B utiliza una arquitectura Mixture of Experts, activando solo las redes neuronales necesarias para cada consulta específica y optimizando así el consumo eléctrico y la velocidad de inferencia. Por su parte, el modelo 31B Dense ofrece la máxima fiabilidad y potencia bruta, destinado a tareas de análisis masivo de datos, integraciones a gran escala y entornos empresariales donde la precisión milimétrica es innegociable.
El veredicto de la comunidad frente a la generación anterior
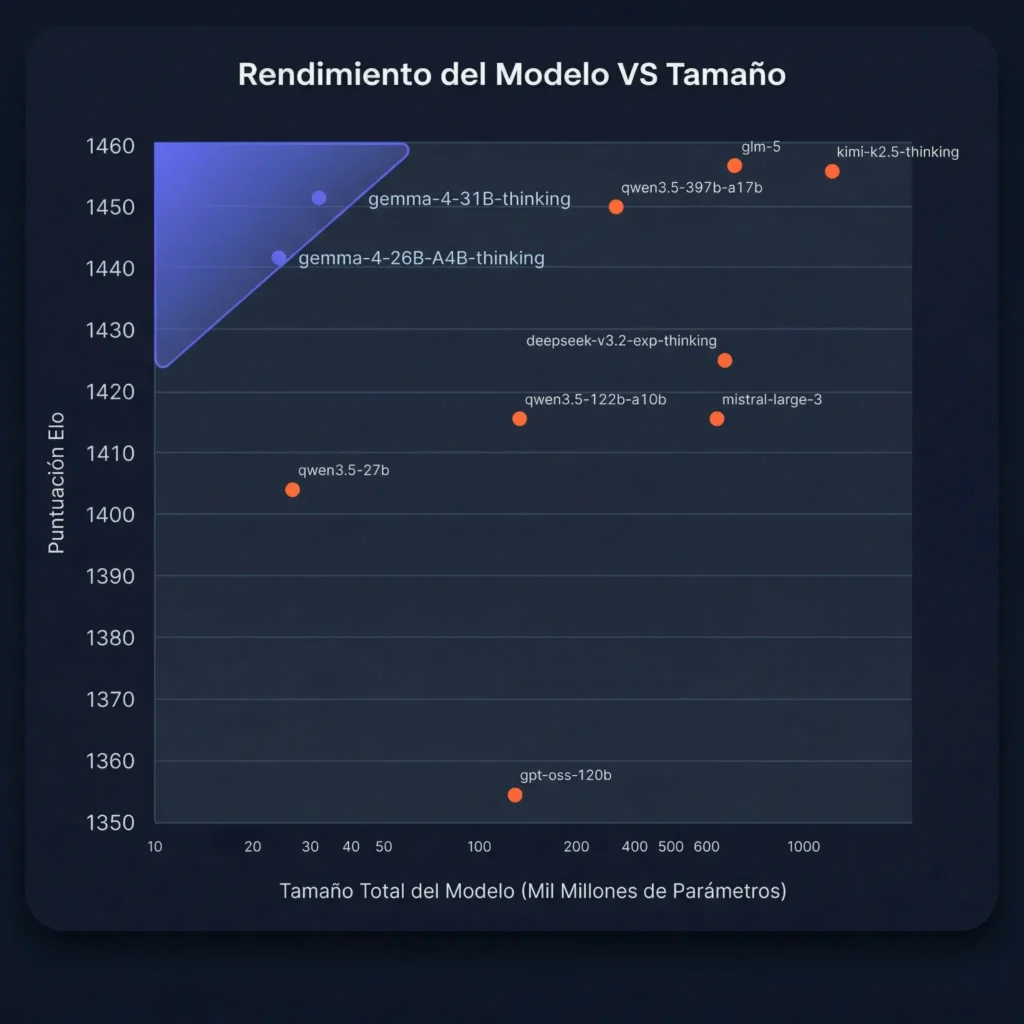
Las pruebas iniciales confirman un salto cualitativo evidente frente a Gemma 3. Uno de los avances más celebrados es la eficacia zero-shot, que elimina la necesidad de incluir múltiples ejemplos previos en el prompt para que el sistema capte el tono deseado. Los usuarios técnicos destacan especialmente la versión 31B por su maestría en la generación de código y diseño frontend, produciendo interfaces coherentes y robustas que prácticamente no requieren depuración. Además, la combinación del nuevo modo de razonamiento con la enorme ventana de contexto garantiza una coherencia a largo plazo excepcional, erradicando las temidas alucinaciones que solían aparecer al procesar textos de gran longitud.
| Benchmark | Gemma 4 31B IT Thinking |
Gemma 4 26B A4B IT Thinking |
Gemma 4 E4B IT Thinking |
Gemma 4 E2B IT Thinking |
Gemma 3 27B IT (Antiguo) |
|---|---|---|---|---|---|
| Arena AI (Texto) A fecha de 2/4/2026 | 1452 | 1441 | — | — | 1365 |
| MMMLU Q&A Multilingüe (Sin herramientas) | 85.2% | 82.6% | 69.4% | 60.0% | 67.6% |
| MMMU Pro Razonamiento multimodal | 76.9% | 73.8% | 52.6% | 44.2% | 49.7% |
| AIME 2026 Matemáticas (Sin herramientas) | 89.2% | 88.3% | 42.5% | 37.5% | 20.8% |
| LiveCodeBench v6 Problemas de código competitivo | 80.0% | 77.1% | 52.0% | 44.0% | 29.1% |
| GPQA Diamond Conocimiento científico (Sin herramientas) | 84.3% | 82.3% | 58.6% | 43.4% | 42.4% |
| τ2-bench Uso de herramientas agénticas (Retail) | 86.4% | 85.5% | 57.5% | 29.4% | 6.6% |
Análisis crítico sobre el impacto laboral y la democratización
Desde una perspectiva ética y profesional en este 2026, el despliegue de estas capacidades en abierto genera un impacto sísmico en el panorama laboral y del desarrollo. Por un lado, democratiza el acceso a herramientas agénticas de vanguardia, permitiendo a desarrolladores independientes construir ecosistemas de IA locales en equipos de gama media sin depender de los oligopolios de la nube. Sin embargo, también eleva drásticamente el estándar mínimo de productividad exigido a los perfiles junior de programación. La facilidad con la que Gemma 4 puede estructurar proyectos complejos localmente sugiere una transición acelerada donde el rol del desarrollador muta definitivamente de picador de código a supervisor de lógica de sistemas y orquestador de agentes autónomos.
Fuentes verificadas
- 01. Página oficial del modelo Gemma 4 y arquitectura base
- 02. Tarjeta de modelo oficial y documentación técnica
- 03. Despliegue de habilidades agénticas en el borde con LiteRT-LM
- 04. Pruebas de la comunidad: ejecución local y requisitos mínimos de RAM
- 05. Presentación oficial y demostración visual del modelo E2B





